
Overview
Apache Spark is an open-source distributed computing system designed to quickly process large volumes of data that can hardly accomplished by operating on a single machine. Spark distributes data and computations across multiple machines, allowing for parallel processing.
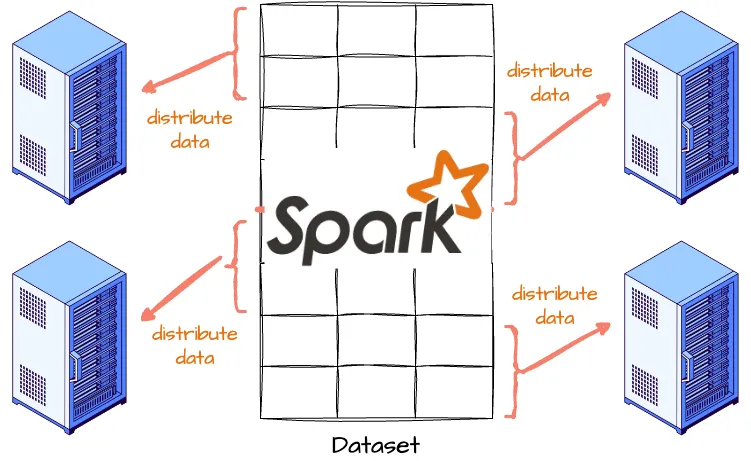
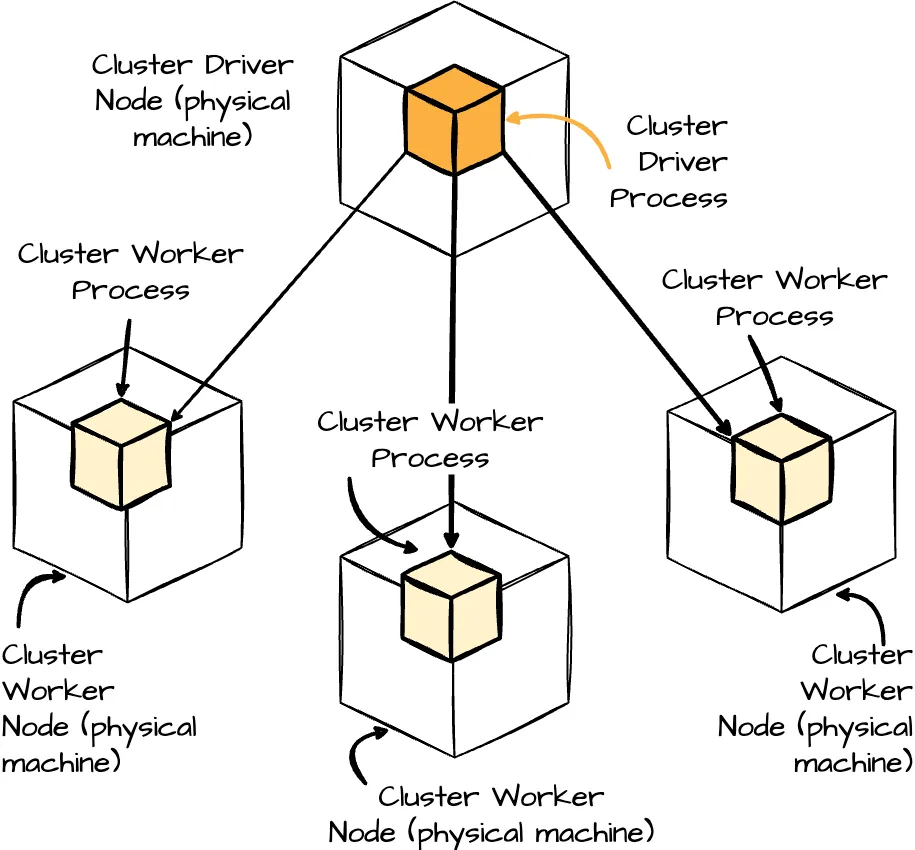
Architecture
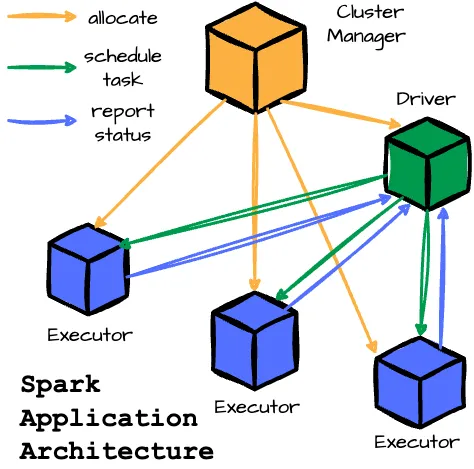
- Driver: This JVM process manages the Spark application, handling user input and distributing work to the executors.
- Cluster Manager: This component oversees the cluster of machines running the Spark application. Spark can work with various cluster managers, including YARN, Apache Mesos, or its standalone manager.
- Executors: These processes execute tasks the driver assigns and report their status and results. Each Spark application has its own set of executors. A single worker node can host multiple executors.
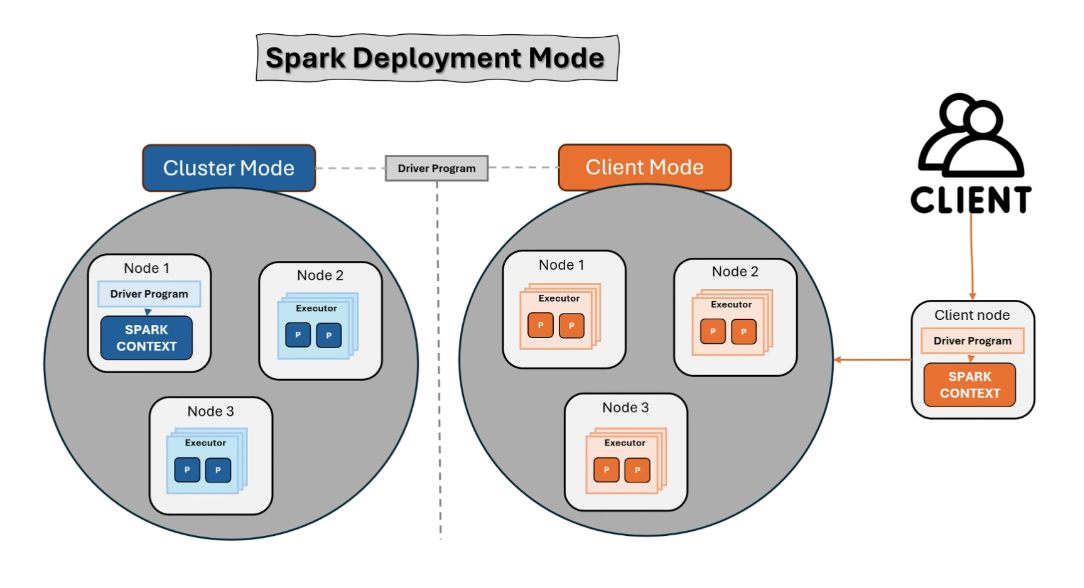
Spark deployment mode
Cluster mode
- Driver Program(Init spark context) node exists in cluster.
- Use in production.
- Leverage efficiently cluster resources and scalability.
Client mode
- Driver Program(Init spark context) place out of the cluster (place at local machine). The cluster have only worker nodes.
- Use in development.
- Execute for small steps, evaluation logic and debug.
Job, Stage, and Task
- Job: In Spark, a job represents a series of transformations applied to data. It encompasses the entire workflow from start to finish.
- Stage: A stage is a job segment executed without data shuffling. Spark splits the job into different stages when a transformation requires shuffling data across partitions.
- Task: A task is the smallest unit of execution within Spark. Each stage is divided into multiple tasks, running the same code on a separate data partition executed by individual executors.
Resilient Distributed Dataset (RDD)
RDD is the primary data abstraction. Whether DataFrames or Datasets are used, they are compiled into RDDs behind the scenes. It represents an immutable, partitioned collection of records that can be operated on in parallel. Data inside RDD is stored in memory for as long and as much as possible.
Key Properties
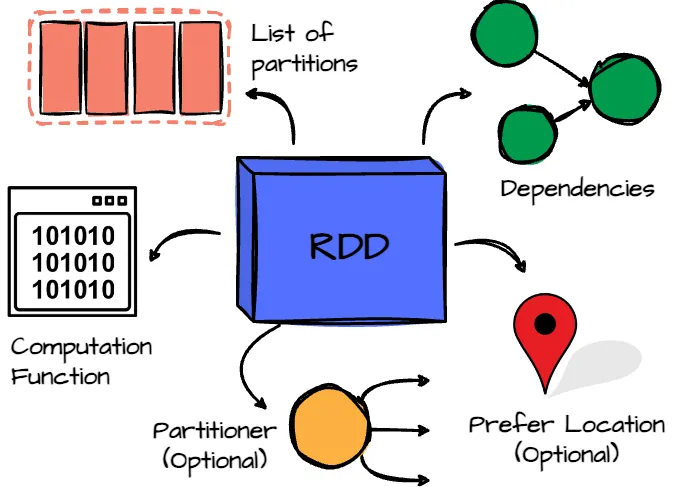
- List of Partitions: The RDD is divided into partitions, which are the units of parallelism in Spark.
- Computation Function: A function determines how to compute the data for each partition.
- Dependencies: The RDD keeps track of its dependencies on other RDDs, which describes how it was created.
- Partitioner (Optional): For key-value RDDs, a partitioner specifies how the data is partitioned, such as using a hash partitioner.
- Preferred Locations (Optional): This property lists the preferred locations for computing each partition, such as the data block locations in the HDFS.
Lazy Evaluation
When you define the RDD, its inside data is not available or transformed immediately until an action triggers the execution. This approach allows Spark to determine the most efficient way to execute the transformations
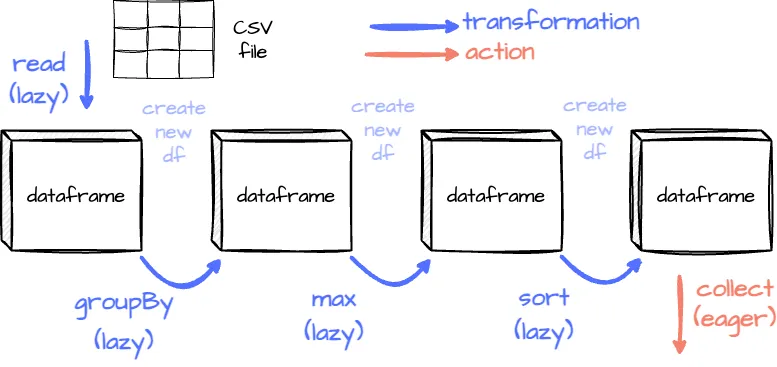 Spark doesn’t modify the original RDD when a transformation is applied to an RDD. Instead, it creates a new RDD that represents the result of applying the transformation because RDD is immutable.
Spark doesn’t modify the original RDD when a transformation is applied to an RDD. Instead, it creates a new RDD that represents the result of applying the transformation because RDD is immutable.
Partitions
When an RDD is created, Spark divides the data into multiple chunks, known as partitions. Each partition is a logical data subset and can be processed independently with different executors. This enables Spark to perform operations on large datasets in parallel.
Fault Tolerance
Spark RDDs achieve fault tolerance through lineage. Spark forms the dependency lineage graph by keeping track of each RDD’s dependencies on other RDDs, which is the series of transformations that created it.
Suppose any partition of an RDD is lost due to a node failure or other issues. In that case, Spark can reconstruct the lost data by reapplying the transformations to the original dataset described by the lineage. This approach eliminates the need to replicate data across nodes. Instead, Spark only needs to recompute the lost partitions, making the system efficient and resilient to failures.
1. Why Apache Spark RDD is immutable?
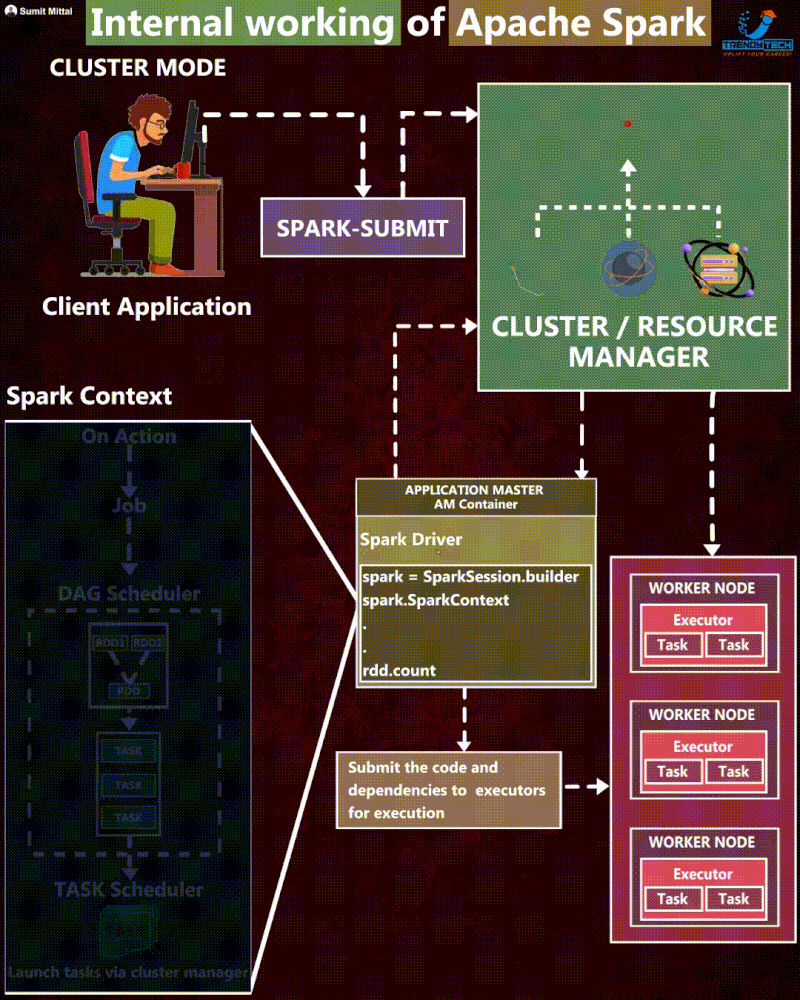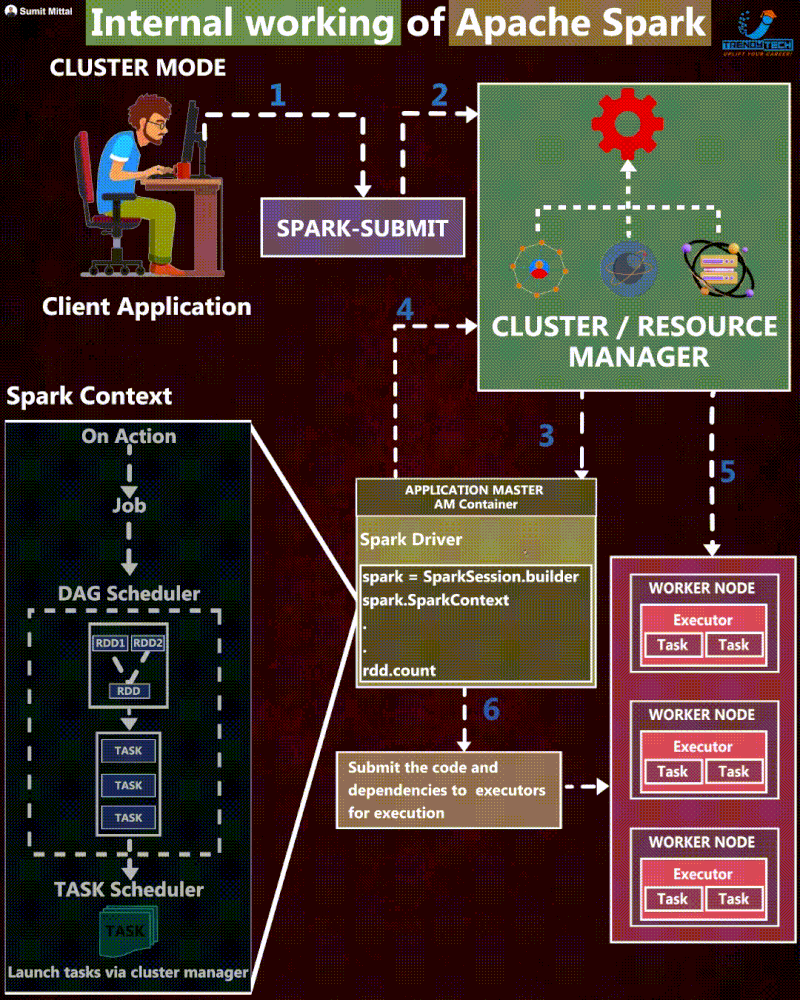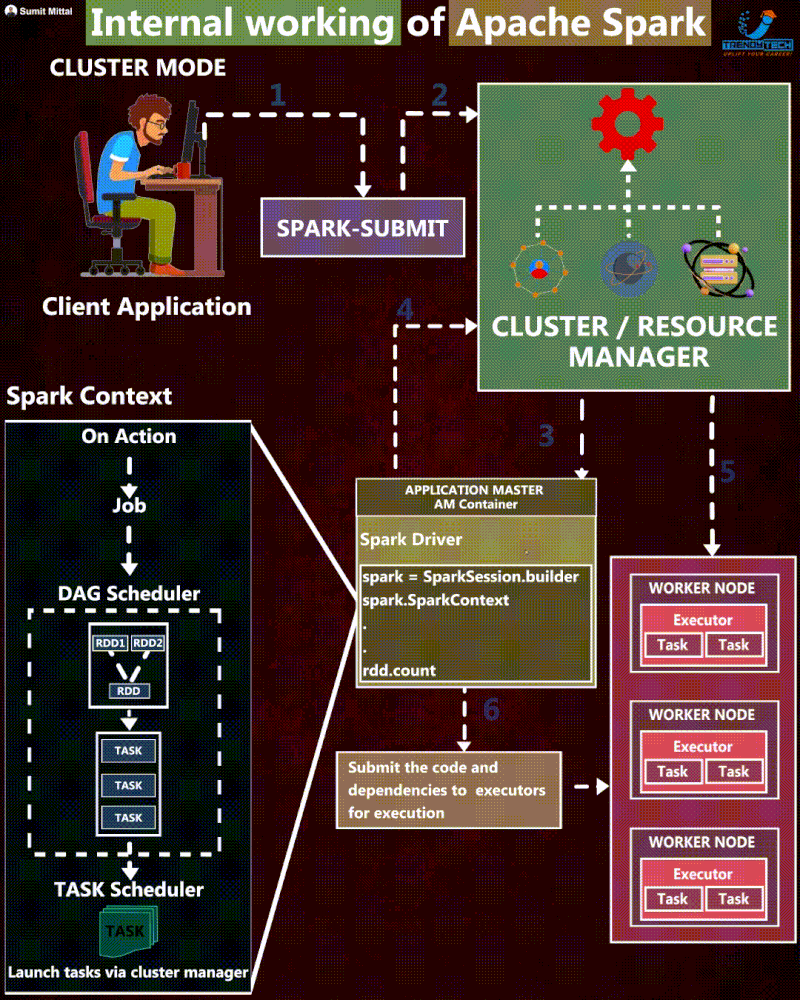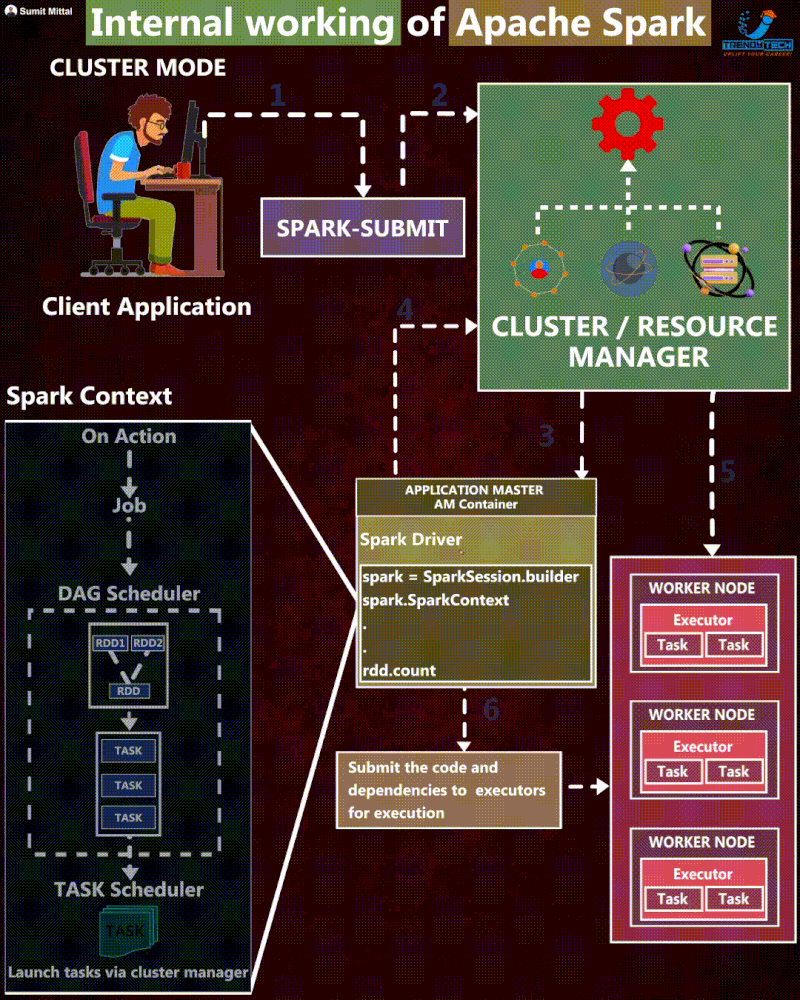
The journey of the Spark application
Execution mode
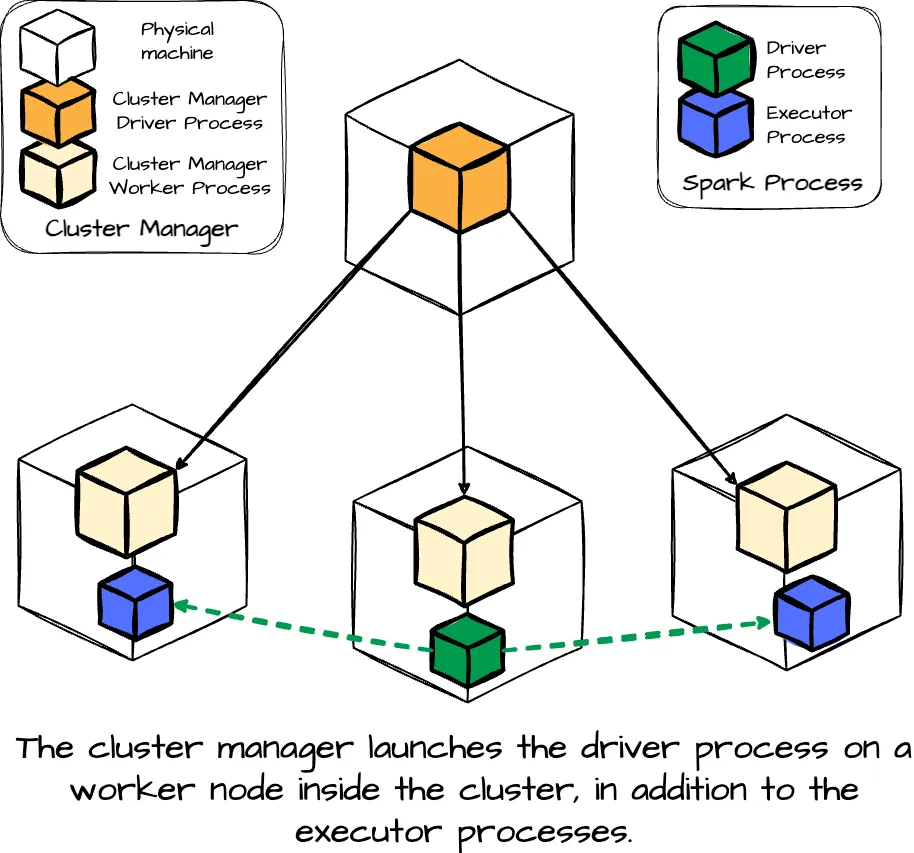
- Cluster Mode: In this mode, the driver process is launched on a worker node within the cluster alongside the executor processes. The cluster manager handles all the processes related to the Spark application.
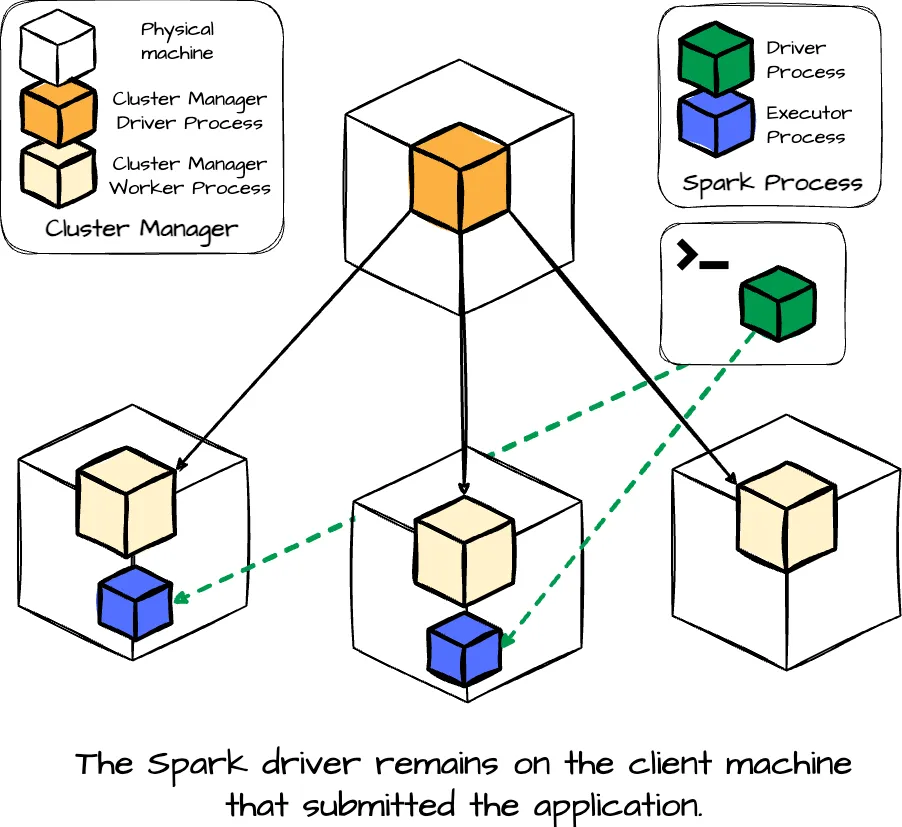
- Client Mode: The driver remains on the client machine that submitted the application. This setup requires the client machine to maintain the driver process throughout the application’s execution.
- Local mode: This mode runs the entire Spark application on a single machine, achieving parallelism through multiple threads. It’s commonly used for learning Spark or testing applications in a simpler, local environment.
Execution Steps
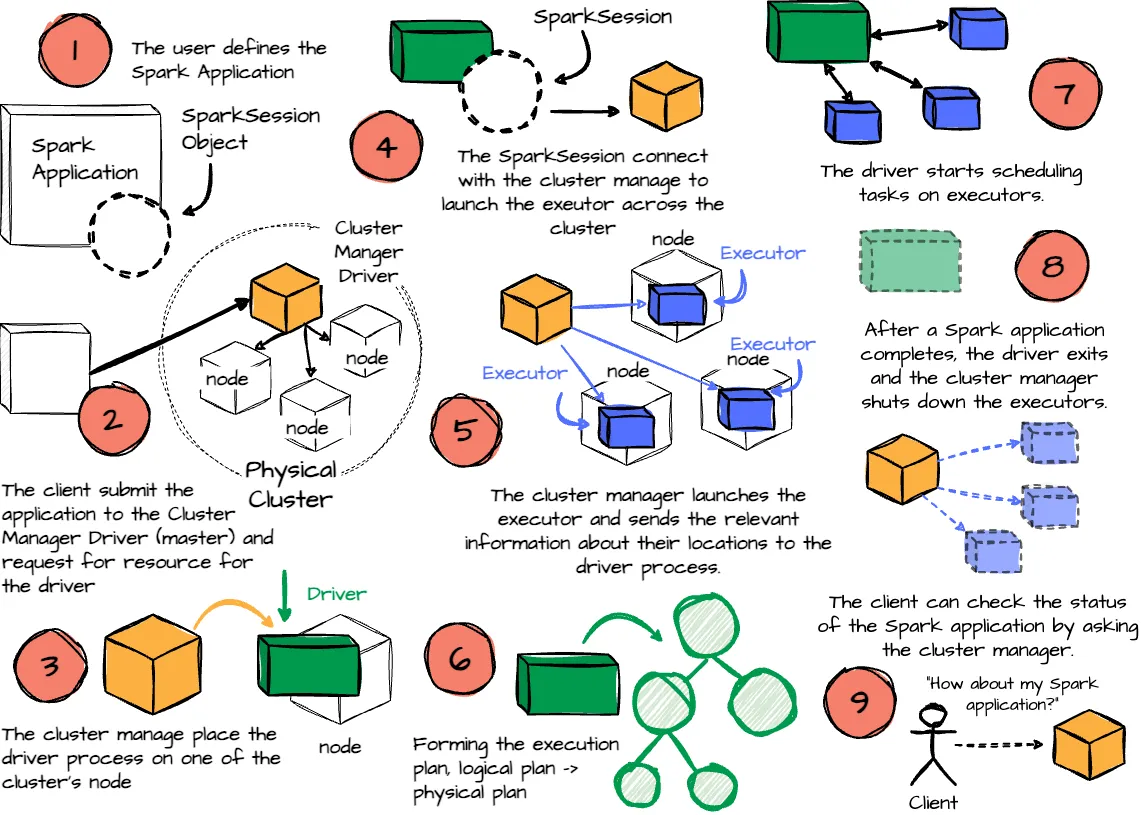
- First, the user defines the Spark Application using their chosen programming language. Every application must include the SparkSession object. This object is the entry point to programming with Apache Spark, which serves as the central gateway for interacting with all of Spark’s functionalities.
- Then, the client submits a Spark application, which is a pre-compiled JAR, to the cluster manager. At this step, the client also requests for the driver resource.
- When the cluster manager accepts this submission, it places the driver process in one of the worker nodes.
- Next, the SparkSession from the application code asks the cluster manager to launch the executors. The user can define the number of executors and related configurations.
- If things go well, the cluster manager launches the executor processes and sends the relevant information about their locations to the driver process.
- Before execution begins, it formulates an execution plan to guide the physical execution. This process starts with the logical plan, which outlines the intended transformations. It generates the physical plan through several refinement steps, specifying the detailed execution strategy for processing the data.
- The driver starts scheduling tasks on executors, and each executor responds to the driver with the status of those tasks.
- After a Spark Application is completed, the driver exits with either success or failure. The cluster manager then shuts down the executors for this application.
- Then, the client can check the status of the Spark application by asking the cluster manager.