
What is RDD?
- RDD stands for Resilient Distributed Dataset.
- An abstraction Spark represent a large collection of data distributed across a node cluster.
- RDD stored in partitions on different nodes across the cluster.
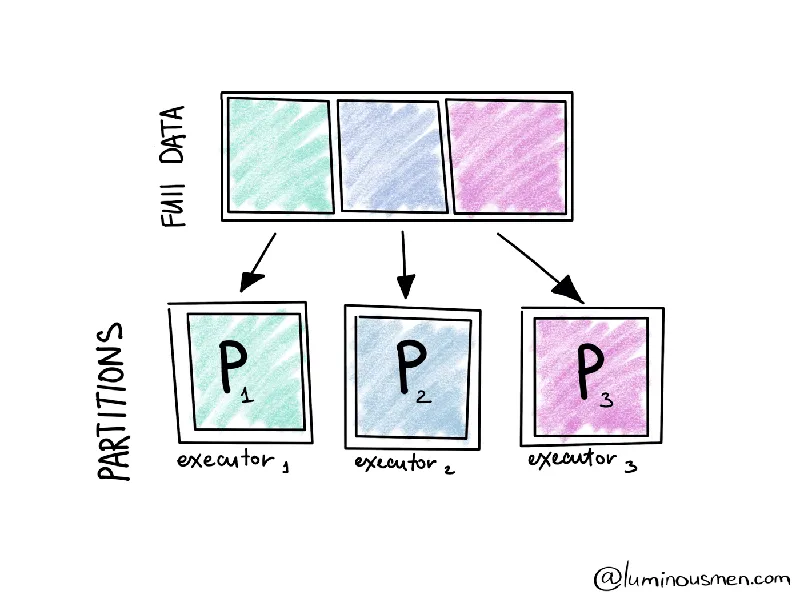
- A partition is essentially a logical chunk of a large distributed dataset.
- Partitions are primary unit of Spark.
Why are RDD immutable?
Important
RDDs are immutable - They can not changed once created and distributed across the cluster’s memory.
Functional Programming Influence
- Immutability ensures that once an RDD created, it can not be changed.
- Any operation on an RDD, it will create a new an RDD.
- So, enhance performance and maintain consistency in distributed system.
Support for concurrent consumption
- RDD designed to support concurrent processing in distributed system
- Immutability ensures that data remains consistent across threads.
- Eliminating the need for complex synchronization mechanisms and reducing the risk of race conditions.
In-Memory Computing
- Immutable data structures eliminate the need for frequent cache invalidation, making it easier to maintain consistency and reliability in a high-performance computing environment.
Lineage and Fault Tolerance
- RDDs provide fault tolerance through a lineage graph - a record of the series of transformations that have been applied.
- Lineage allows Spark to reconstruct a lost or corrupted RDD by tracing back through its transformation history.
- Immutability ensures that the lineage information remains intact and allows Spark to recompute lost data reliably.