
Overview
Let’s walk through the execution of a single structured API query from user code to executed code. Here’s an overview of the steps:
- Write DataFrame/Dataset/SQL Code.
- If valid code, Spark converts this to a Logical Plan.
- Spark transforms this Logical Plan to a Physical Plan, checking for optimizations along the way.
- Spark then executes this Physical Plan (RDD manipulations) on the cluster.
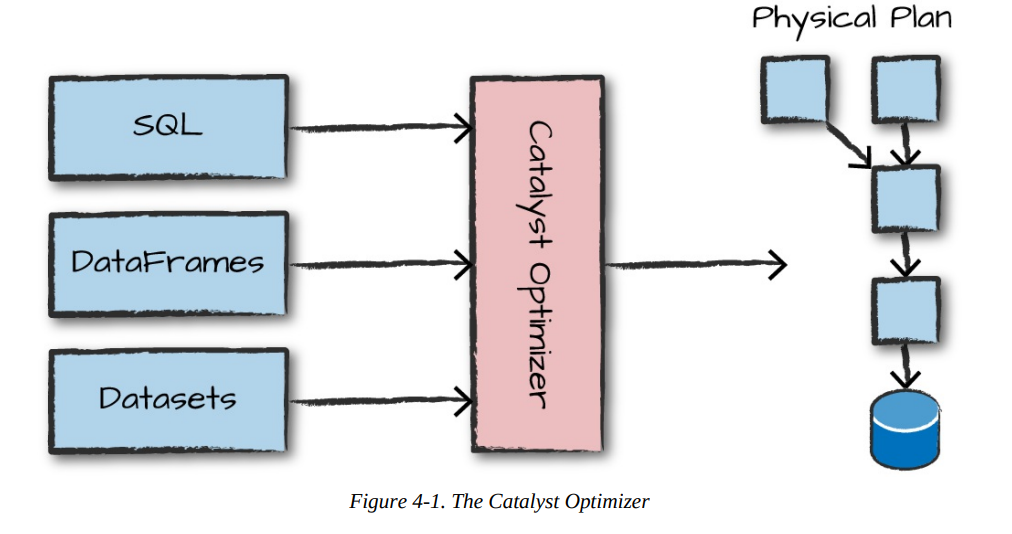
To execute code, we must write code. This code is then submitted to Spark either through the console or via a submitted job. This code then passes through the Catalyst Optimizer, which decides how the code should be executed and lays out a plan for doing so before, finally, the code is run and the result is returned to the user.
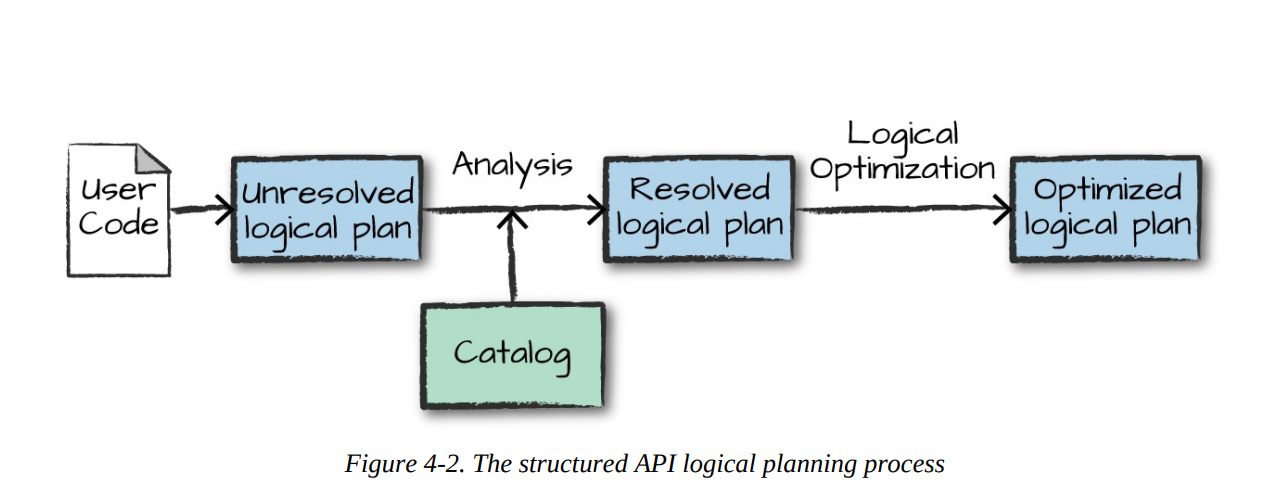
Logical Planing
 Example:
Example:
import spark.implicits._
val data1 = Seq(("1", "Java", "20000"),
("2", "Python", "100000"),
("3", "Scala", "3000"))
// Create languages DF
val languages = spark.createDataFrame(data1)
.toDF("id","language","tution_fees")
// Create temporary view
languages.createOrReplaceTempView("languages")
val data2 = Seq(("1", "studentA"), ("1", "studentB"),
("2", "studentA"), ("3", "studentC"))
// Create students DF
val students = spark.createDataFrame(data2).toDF("language_id","studentName")
// Create temporary view
students.createOrReplaceTempView("students")
// Join tables
val df =spark.sql("""SELECT students.studentName, SUM(students.language_id) as c
FROM students
INNER JOIN languages
ON students.language_id= languages.id
WHERE students.studentName ='studentA'
group by students.studentName""")Unresolved logical plan: verifying the syntactic fields in the query, and next the semantic analysis is executed on top of it.
df.explain(extended=true)
// Output(First Plan)
== Parsed Logical Plan ==
'Aggregate ['students.studentName], ['students.studentName, 'SUM('students.language_id) AS c#1539]
+- 'Join Inner, (('students.language_id = 'languages.id) AND ('students.studentName = studentA))
:- 'UnresolvedRelation [students], [], false
+- 'UnresolvedRelation [languages], [], falseCatalog: Spark uses the catalog, a repository of all table and DataFrame information, to resolve columns and tables in the analyzer. The analyzer might reject the unresolved logical plan if the required table or column name does not exist in the catalog.
Resolve logical plan: Using the Schema Catalog to validate the table or column objects, the logical plan has now resolved everything it was unable to in the unresolved logical plan. (In this catalog, which can be connected to a metastore, a semantic analysis will be produced to verify data structures, schemas, types, etc. and if everything goes well, the plan is marked as “Analyzed Logical Plan”.)
df.explain(extended=true)
// Output(Second Plan)
== Analyzed Logical Plan ==
studentName: string, c: double
Aggregate [studentName#1536], [studentName#1536, sum(cast(language_id#1535 as double)) AS c#1539]
+- Join Inner, ((language_id#1535 = id#1525) AND (studentName#1536 = studentA))
:- SubqueryAlias students
: +- View (`students`, [language_id#1535,studentName#1536])
: +- Project [_1#1531 AS language_id#1535, _2#1532 AS studentName#1536]
: +- LocalRelation [_1#1531, _2#1532]
+- SubqueryAlias languages
+- View (`languages`, [id#1525,language#1526,tution_fees#1527])
+- Project [_1#1519 AS id#1525, _2#1520 AS language#1526, _3#1521 AS tution_fees#1527]
+- LocalRelation [_1#1519, _2#1520, _3#1521]Optimized logical plan: Once the Resolved Logical plan has been produced, Catalyst optimizer helps to optimize the resolved logical plan using various rules applied on logical operations.
df.explain(extended=true)
// Output(Third Plan)
== Optimized Logical Plan ==
Aggregate [studentName#1536], [studentName#1536, sum(cast(language_id#1535 as double)) AS c#1539]
+- Project [language_id#1535, studentName#1536]
+- Join Inner, (language_id#1535 = id#1525)
:- LocalRelation [language_id#1535, studentName#1536]
+- LocalRelation [id#1525]Physical Planning (Spark plan)
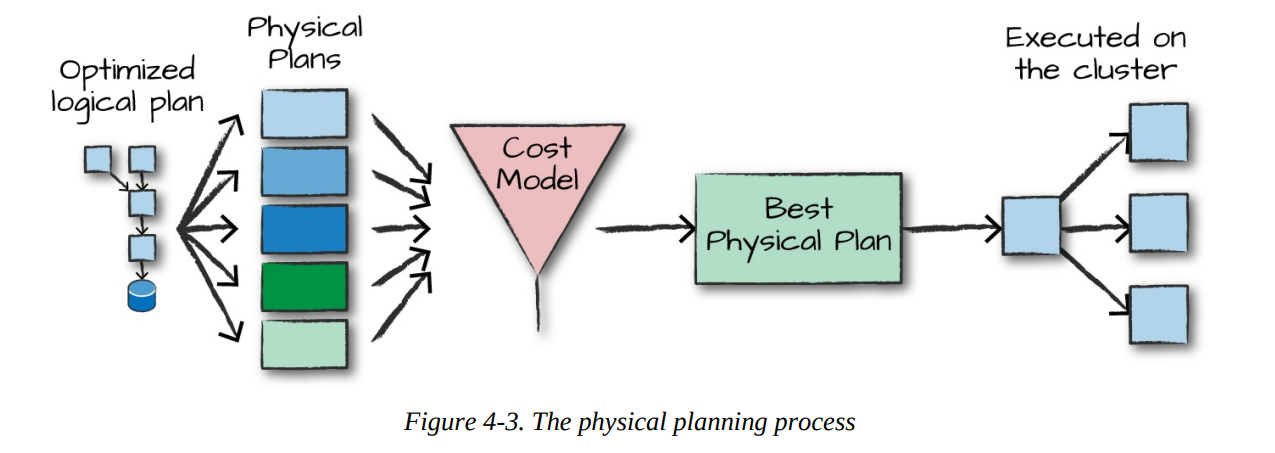
The spark will conduct to process physical plan after creating an optimized logical plan.
Spark Plan
That is specifies how the logical plan will execute on the cluster by generating different physical execution strategies and comparing them through a cost model.
df.explain(extended=true)
// Output(Last Plan)
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[studentName#1536], functions=[finalmerge_sum(merge sum#1544) AS sum(cast(language_id#1535 as double))#1540], output=[studentName#1536, c#1539])
+- Exchange hashpartitioning(studentName#1536, 200), ENSURE_REQUIREMENTS, [id=#1028]
+- HashAggregate(keys=[studentName#1536], functions=[partial_sum(cast(language_id#1535 as double)) AS sum#1544], output=[studentName#1536, sum#1544])
+- Project [language_id#1535, studentName#1536]
+- BroadcastHashJoin [language_id#1535], [id#1525], Inner, BuildRight, false
:- LocalTableScan [language_id#1535, studentName#1536]
+- BroadcastExchange HashedRelationBroadcastMode(ArrayBuffer(input[0, string, true]),false), [id=#1023]
+- LocalTableScan [id#1525]Adaptive Query Execution has a new feature in Spark 3.0 that enables spark execution physical plan changes at runtime of the query on the cluster. Based on the query plan execution statics, at runtime spark changes to the better plan.
In the output of the EXPLAIN() method, it always mentions as this physical plan is not the final plan. Only in spark UI we can see the final plan due to Adoptive Query Execution turned ON, it finalizes the plan on the fly based on the execution statistics.
How does the Catalyst Optimizer choose the best physical plan?
Research
References
- Spark: The Definitive Guide by Bill Chambers and Matei Zaharia.