Jobs, Stages, and Tasks
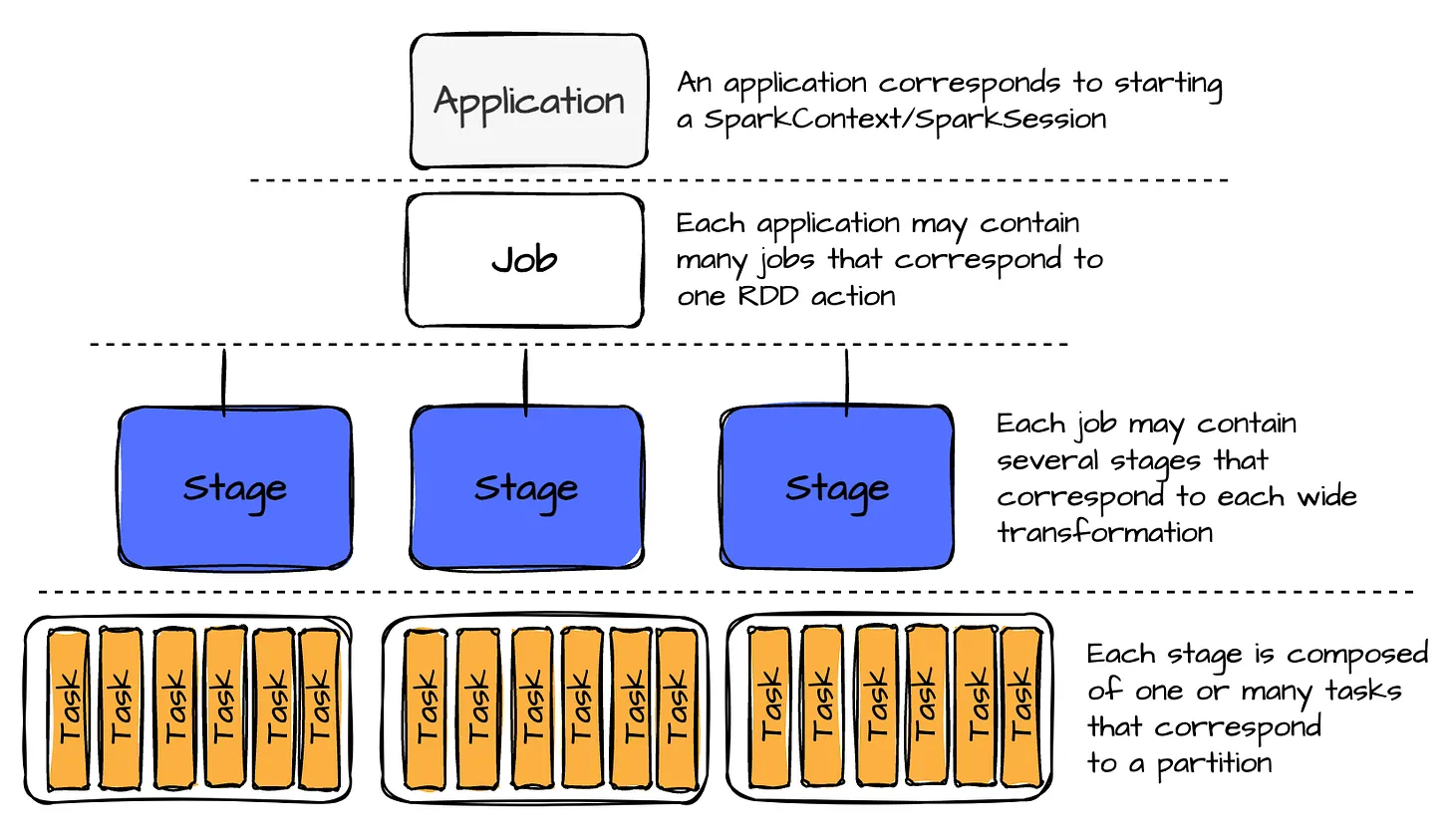
Job
- a job represent a series of transformations applied to data
- A single Spark Application can have more one job
Stage
- A stage is a job segment executed without data shuffling.
- Spark splits the job into different stages when a transformation requires shuffling data across partitions. Speaking of transformations, there are two categories we need to explore:
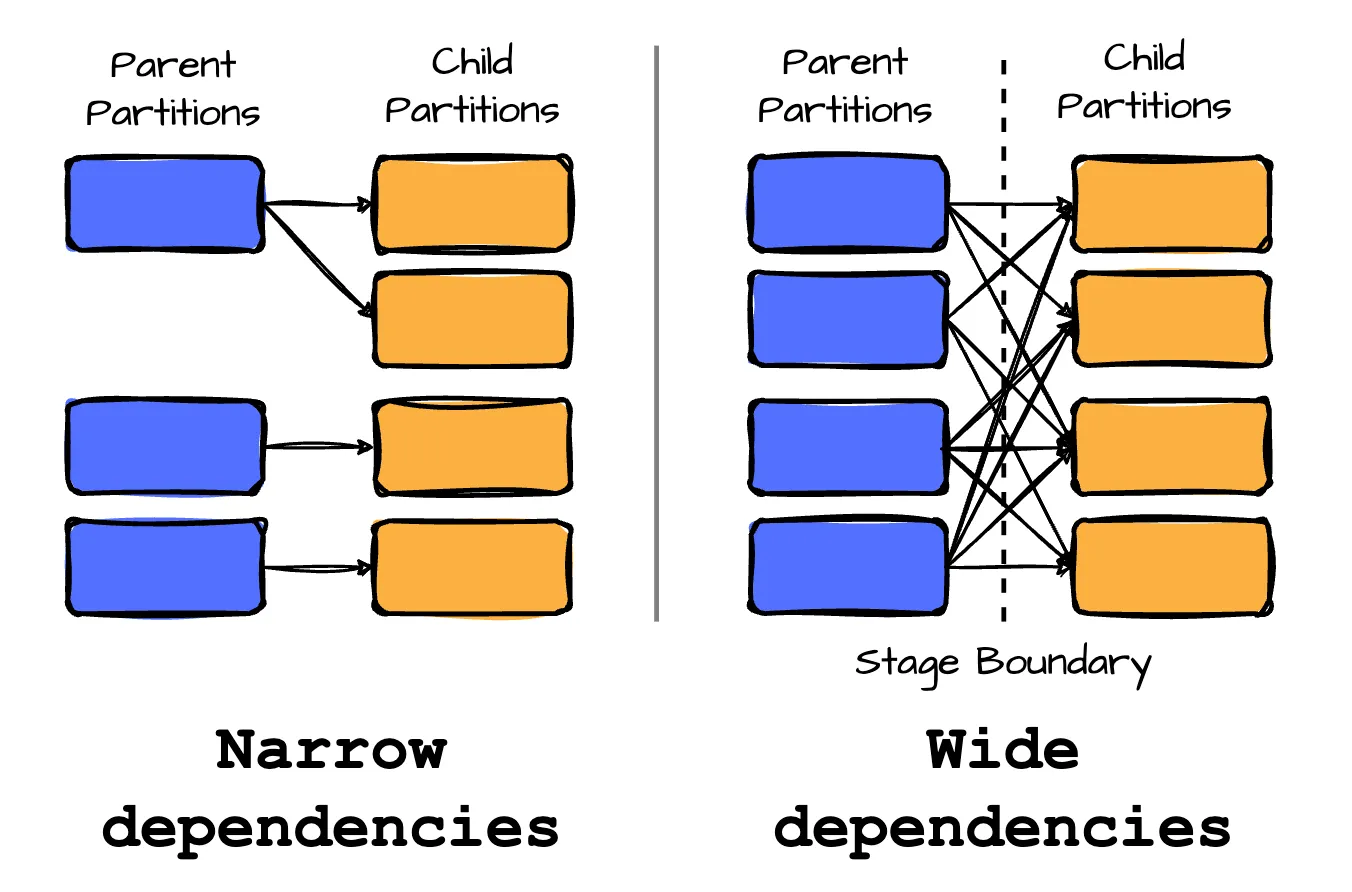
- Transformations with narrow dependencies are those where each partition in the child RDD has a limited number of dependencies on partitions in the parent RDD. These partitions may depend on a single parent (e.g., the map operator) or a specific subset of parent partitions known beforehand (such as with coalesce). This means that operations like map and filter do not require data shuffling. RDD operations with narrow dependencies are pipelined into one set of tasks in each stage.
- Transformations with wide dependencies require data to be partitioned in a specific way, where a single partition of a parent RDD contributes to multiple partitions of the child RDD. This typically occurs with operations like groupByKey, reduceByKey, or join, which involve shuffling data. Consequently, wide dependencies result in stage boundaries in Spark’s execution plan.
Task
A task is the smallest unit of execution within Spark. Each stage is divided into multiple tasks, which execute processing in parallel across different data partitions.
DAG
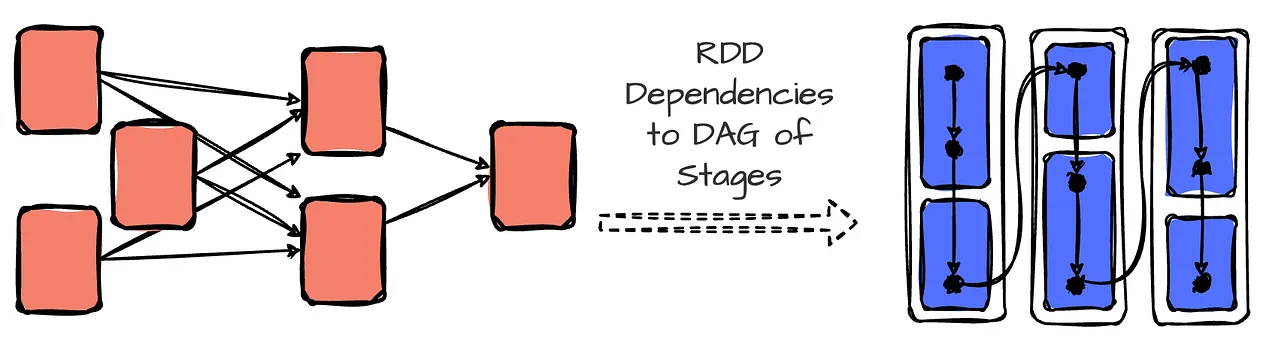
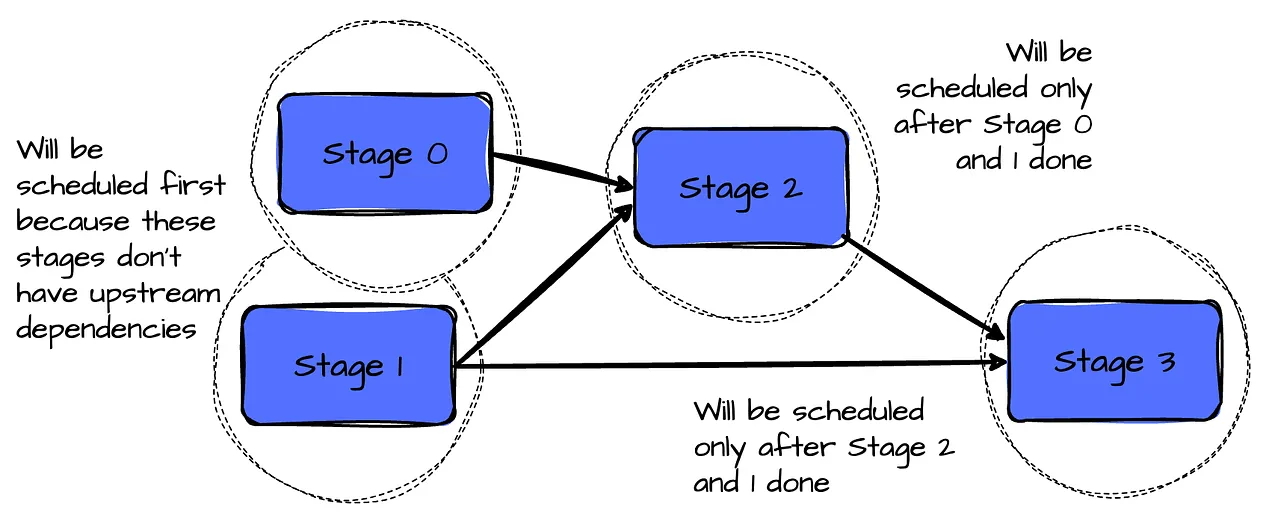
In Spark, the DagScheduler (more on this later) uses RDD dependencies to build a Directed Acyclic Graph (DAG) of stages for a Spark job. The DAG ensures that stages are scheduled in topological order.
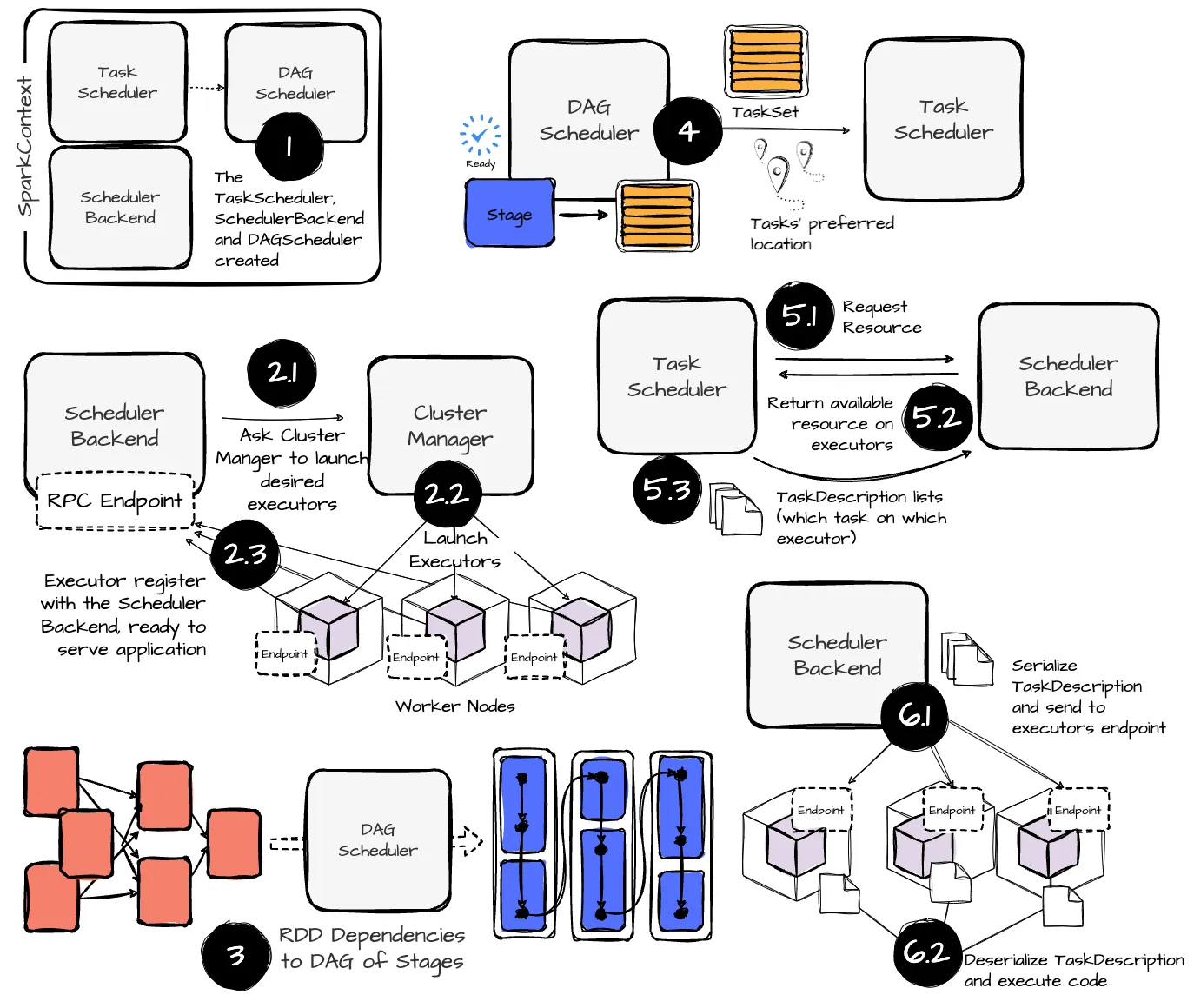
The scheduling process
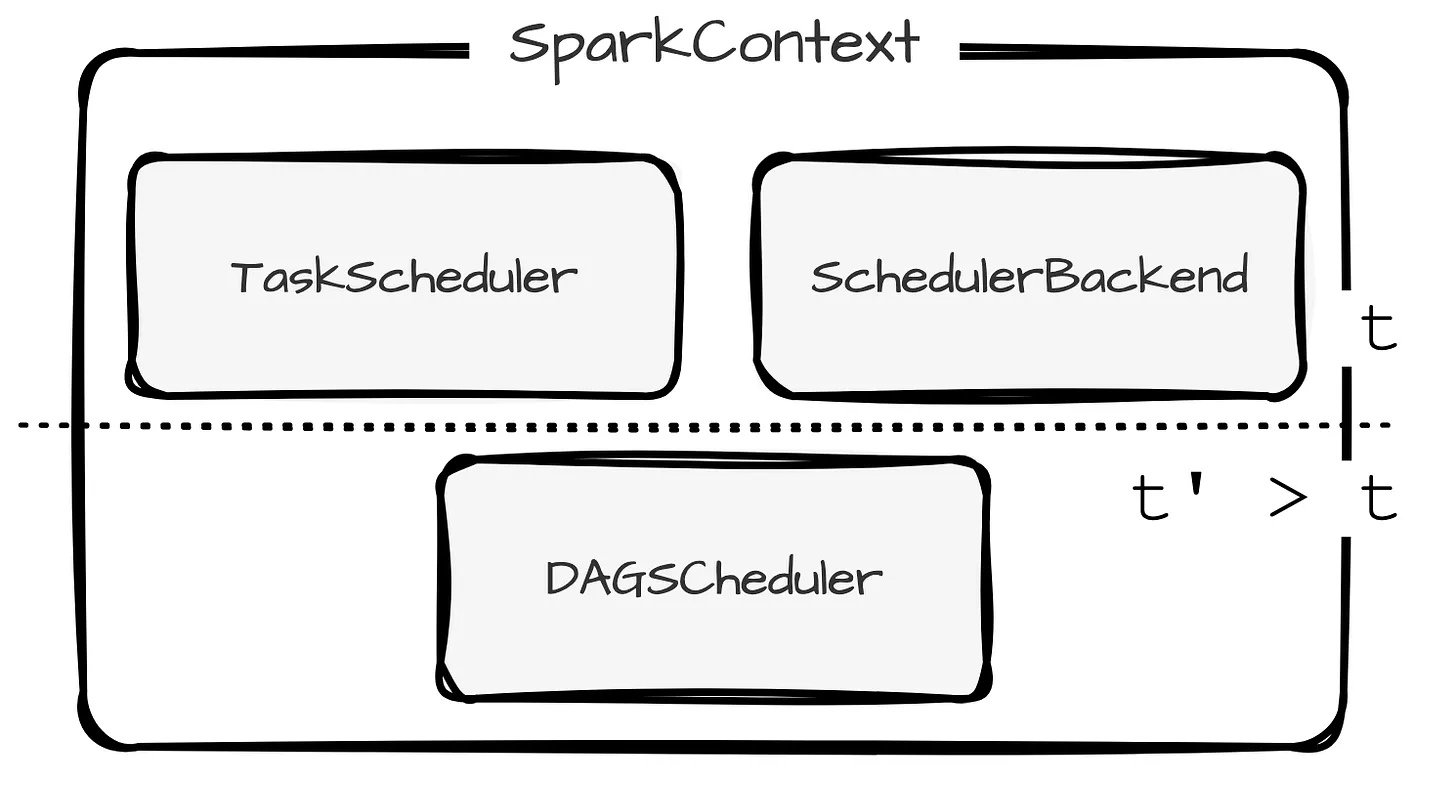
SparkContext
SparkContext is the entry point to all Spark’s components.
SparkContext
The SparkContext then initializes → TaskScheduler and SchedulerBackend → DAGScheduler
DAGScheduler
- DAGScheduler is start first to building DAG of stages based on the dependencies between RDDs.
- The DAGScheduler go through RDD lineage (bottom-up: from final RDD (with action) to the source RDD).
- Stages are formed where wide dependencies (shuffle boundaries) exist.
- Each stage consists of parallel tasks that can be executed on different partitions. Stages are created as ResultStages (final stage) or ShuffleMapStages (intermediate stages that perform shuffles).
- Each stage is submitted once all parent stages (upstream dependencies) are completed.
- The DAGScheduler is responsible for handle failures from previous stages. It will retry these tasks several tiimes before cancelling the whole stage.
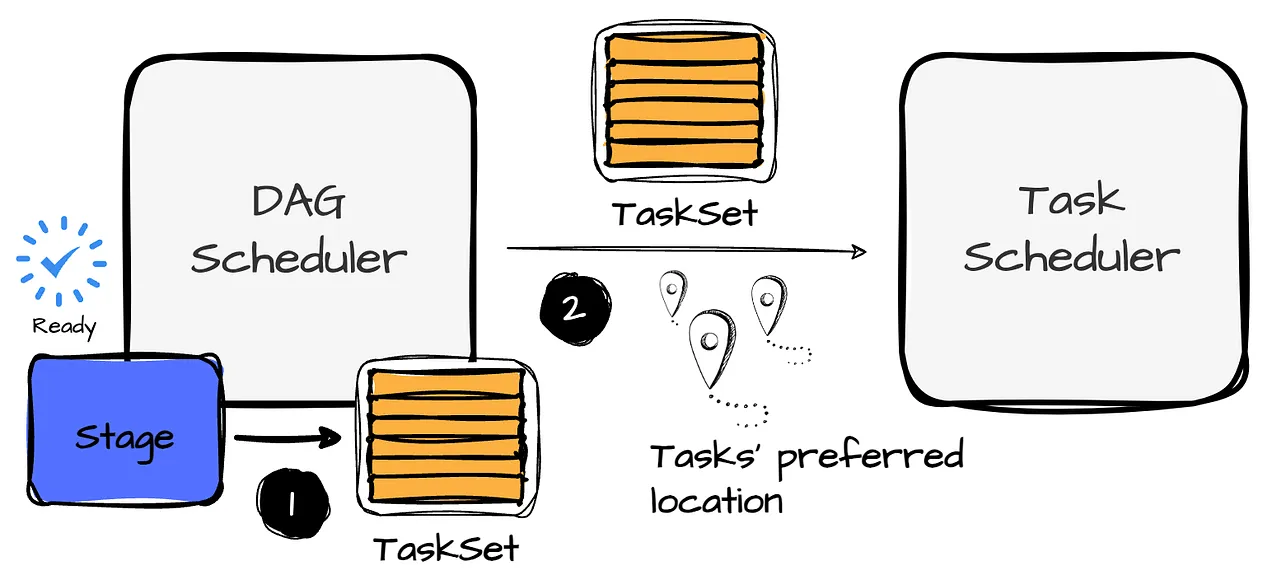
- The DAGScheduler creates a TaskSet for each stage. A TaskSet includes fully independent tasks of a stage that are uncomputed.
- TaskSet is sent to the TaskScheduler for execution. In addition, the DAGS scheduler determines the preferred locations to run each task based on the current cache status and sends these to the TaskScheduler.
Cache tracking
The DAGScheduler detected with RDDs are cached to avoid recomputing them and remembers which shuffle map stages have produced which output files to avoid duplicate process.
Preferred locations
The DAGScheduler also computes where to run each task in a stage based on the preferred locations of its underlying RDDs, or the location of cached or shuffle data.
TaskScheduler
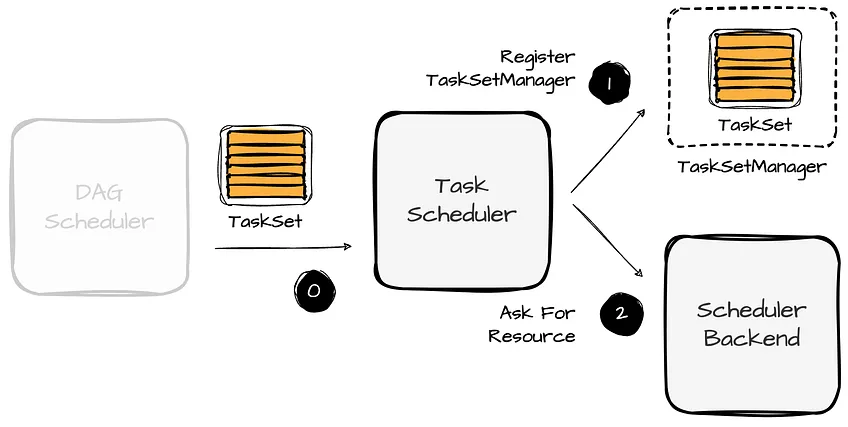
- TaskScheduler is responsible for scheduling tasks on available executors (interact with SchedulerBackend).
- When the DAGScheduler submits a TaskSet to the TaskScheduler, the TaskScheduler registers a new TaskSetManager and requests the SchedulerBackend to handle resource allocation offers.
The TaskSetManager is responsible for:
- Scheduling the tasks in a single TaskSet, and keep track of each task, retries tasks if they failed and handles locality-aware scheduling.
- Tries to assign tasks to executors as close to the data as possible.
Data Locality Types (nearest to farthest)
- PROCESS_LOCAL: Task runs on the same executor where the data resides.
- NODE_LOCAL: The task runs on the same node as the data but on a different executor.
- NO_PREF data is accessed equally quickly from anywhere and has no local preference.
- RACK_LOCAL: The task runs on the same rack but on a different node.
- ANY: The task can run on any executor when no locality preferences are satisfied.
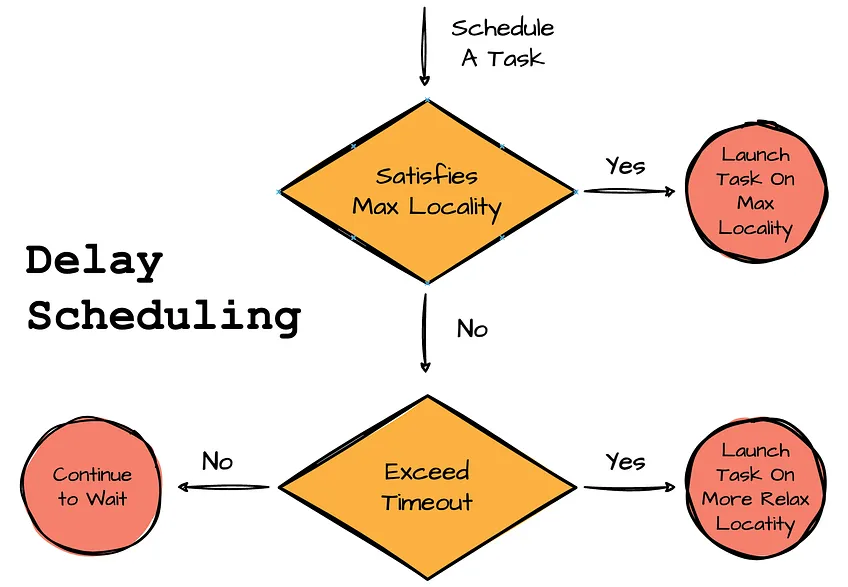
TasksetManager tries to achieve local locality-aware scheduling for a TaskSet by leveraging delay scheduling. This optimization technique has a simple idea: if a task cannot be scheduled on an executor with the desired locality level, TasksetManager will wait a short period before scheduling the task.
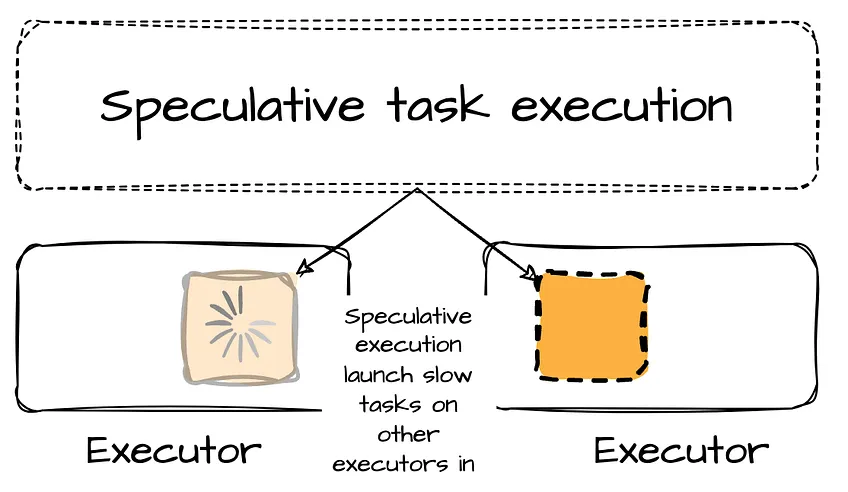
There are cases when some tasks might take longer than other tasks (e.g., due to hardware problems). In the TaskSetManager, there is a health-check procedure called Speculative execution of tasks (enabled by setting spark.speculation = true )that checks for tasks to be speculated. Such slow tasks will be re-submitted to another executor. (This means that issues caused by hardware problems can be mitigated with speculative execution.)
Important
TaskSetManager will not stop the slow tasks but launch a copy of that task in parallel. The first copy of the task that is completed successfully will be used, and other copies will be killed.
SchedulerBackend
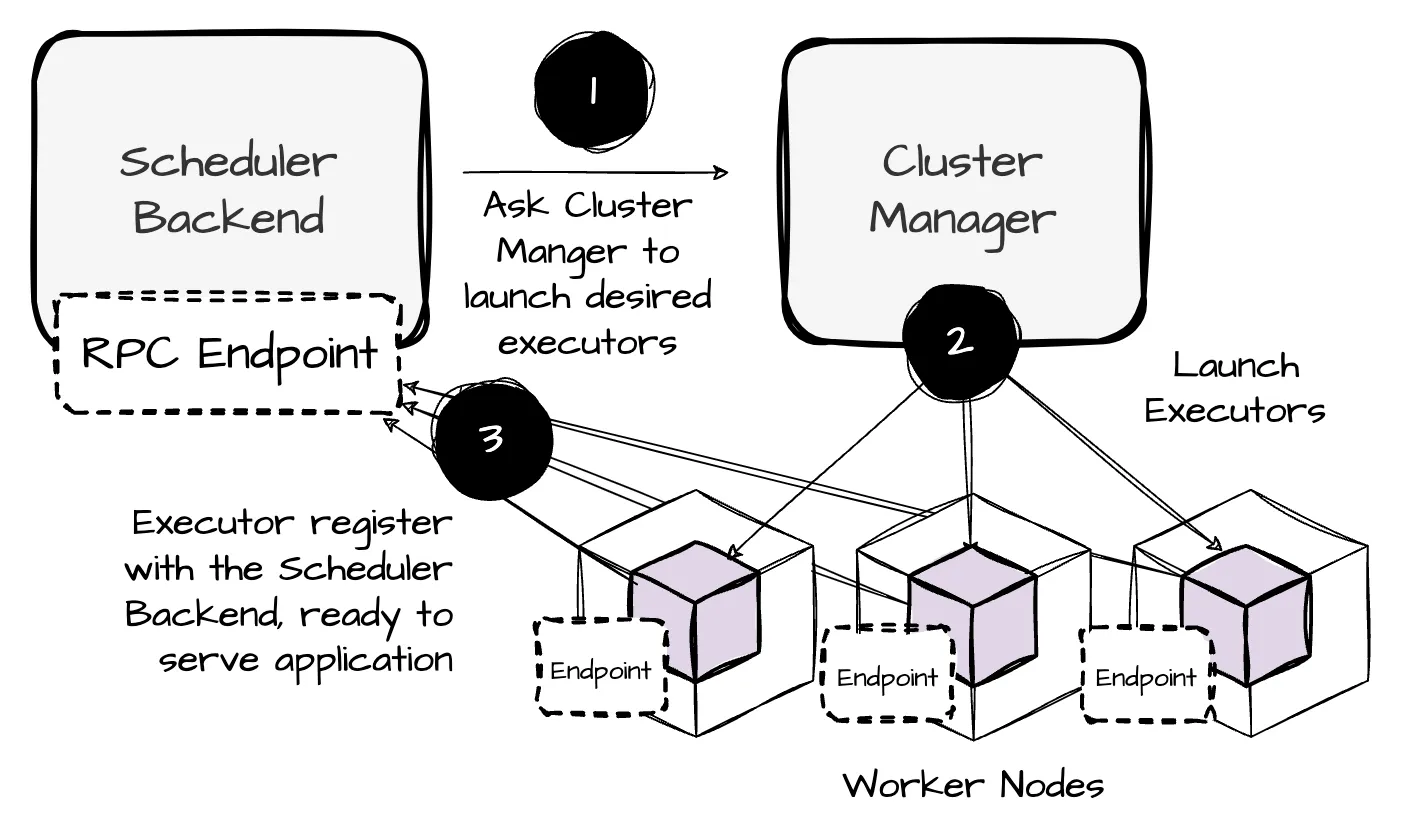
- The SchedulerBackend requests executors from the cluster manager
- Once started, the executors attempt to register with the SchedulerBacked through an RPC endpoint. If successful, the SchedulerBackend receives a list of the application’s desired exectuors
- When the TaskScheduler creates the TaskSetManager, it requests resources from the SchedulerBackend to schedule the tasks. Based on the list of active executors, the SchedulerBackend retrieves WorkerOffers, each representing an executor’s available resources.
Info
Based on the Spark source code, active executors are those that are registered and are not pending removal, have not been lost without reason, and are not being decommissioned.
- Then, the SchedulerBackend passes the WorkerOffers back to the TaskScheduler. The TaskScheduler assigns tasks from the TaskSet to the resources from the WorkerOffers, resulting in a list of task descriptions. These task descriptions are then returned to the SchedulerBackend, which launches tasks based on this task description list.
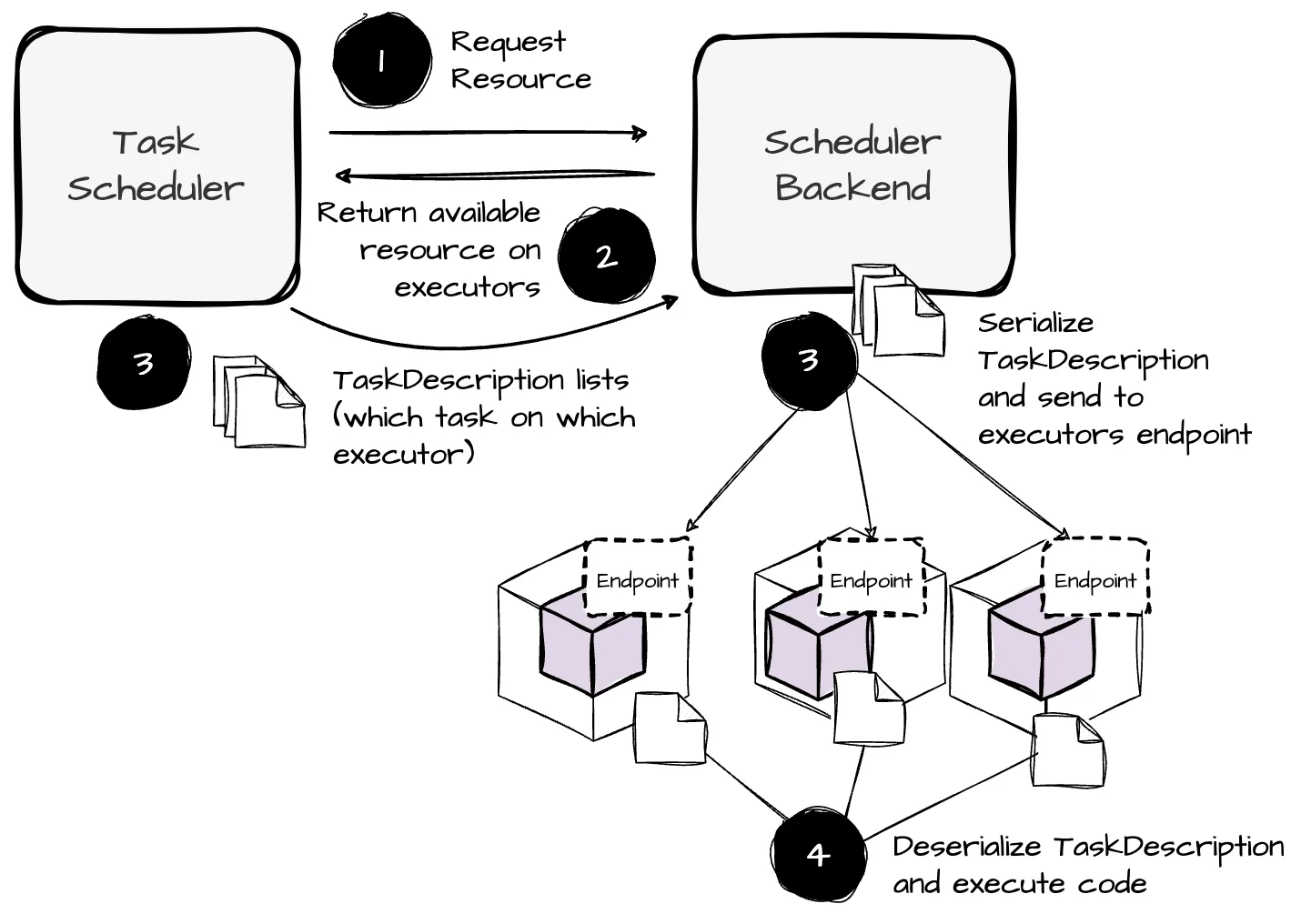
For each entry in this list, the SchedulerBackend serializes the task description. Additionally, it pulls the executor ID assigned to the task from the entry and uses this ID to retrieve information for that executor (e.g., hostname, cores, executor address, executor endpoint).
Finally, the SchedulerBackend sends the serialized task descriptions to the executor endpoints.
Task Execution on Executors
When receiving a serialized task description from the SchedulerBackend, the executor deserializes the task description and begins launching the task using the information provided.
During its lifecycle, the executor runs user-defined code, reads data from local or remote storage, performs computations, and writes out intermediate results, such as shuffle data.
Summary
- The process continues until all stage tasks are finished, with stages being processed in the DAG order. A Spark job is considered complete when all stages have finished.