Spark SQL
First, it provides a seamless integration between relational and procedural processing through a declarative DataFrame API that works smoothly with procedural Spark code. Second, it incorporates a highly extensible optimizer, Catalyst, which leverages Scala’s features to facilitate the addition of composable rules and manage code generation
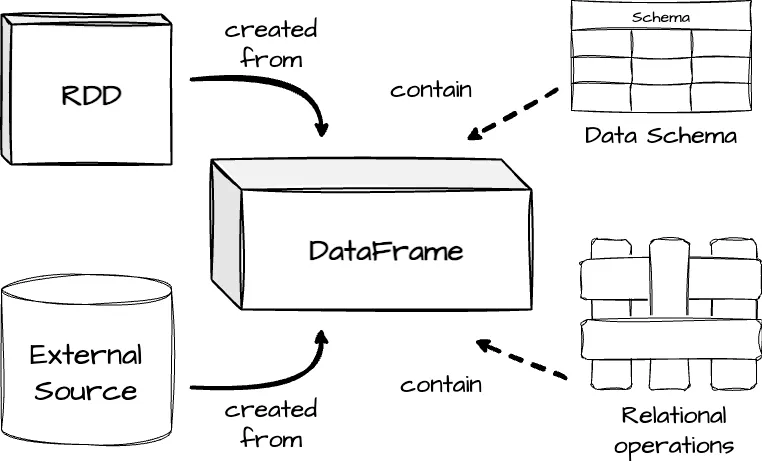
Another important note: unlike the traditional dataframe APIs (e.g., Pandas Dataframe), Spark Dataframe is lazy. Each DataFrame object represents a logical plan to compute a dataset, but no execution occurs until the user calls a special output operation. (This is similar to the transformation and action in RDD.)
Catalyst Optimizer
Catalyst supports both rule-based and cost-based optimization.
- Rule-Based Optimization (RBO): Rule-based optimization in databases relies on a set of predefined rules and heuristics to choose the execution plan for a query. These rules are usually based on the structure of the query, the operations involved, and the database schema. The optimizer applies these rules in a fixed order, without considering the actual data distribution or workload.
- Cost-Based Optimization (CBO): Cost-based optimization, on the other hand, uses statistical information about the data—such as table size, index selectivity, and data distribution—to estimate the cost of various execution plans. The optimizer evaluates multiple potential plans and chooses the one with the lowest estimated cost. However, it requires accurate statistics available. Essentially, Catalyst includes a general library for representing trees and applying rules to manipulate them. Developers can extend Catalyst to support desired external data sources and user-defined types
When we define the DataFrame transformation logic, before the actual execution, it must go through an optimized process that contains four phases: analyzing a logical plan, optimizing the logical plan, physical planning, and finally, code generation.
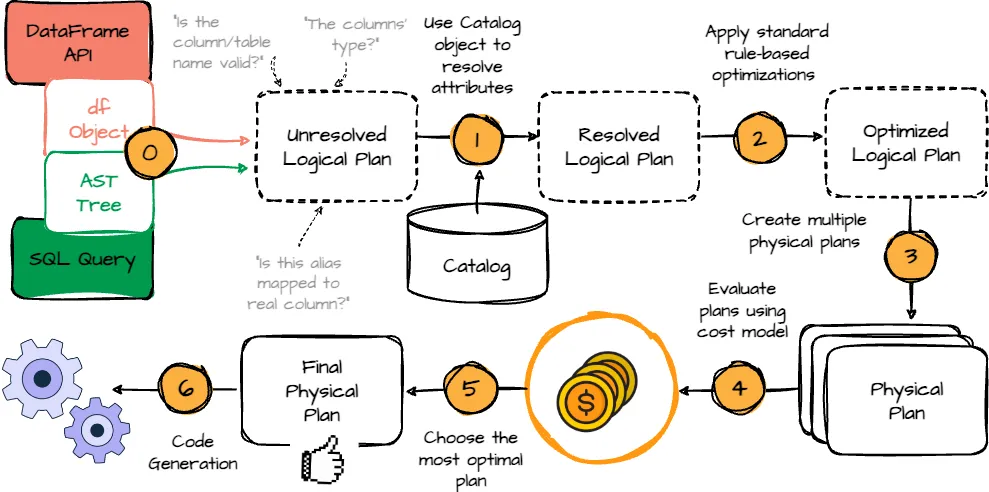
We will visit each phase below:
- Analysis: The first phase begins with a relation to be processed. It can come from the abstract syntax tree retrieved from the SQL parser or the DataFrame object defined using the DataFrame API. Both cases have unresolved attribute references or relations; is the column/table name valid? What is the columns’ type? Spark SQL uses Catalyst rules and a Catalog object to resolve these attributes. It starts by building an “unresolved logical plan” tree with unbound attributes and data types, then applies predefined rules to resolve attributes.
The Spark SQL Catalog
The Spark SQL Catalog object enables interaction with metadata for databases, tables, and functions. It allows users to list, retrieve, and manage these entities, as well as refresh table metadata to keep Spark’s view in sync with underlying data sources. It’s a central interface for managing and querying Spark SQL metadata.
- Logical Optimization: After resolving the logical plan, Spark applies standard rule-based optimizations, such as predicate pushdown, projection pruning, null propagation, and more.
- Physical Planning: Spark SQL takes a logical plan and generates one or more physical plans. It will select the final plan using a cost model.
- Code Generation: The final query optimization phase involves generating Java bytecode for execution. Spark SQL uses code generation to speed up processing, especially for CPU-bound in-memory datasets. Catalyst simplifies this by leveraging Scala’s quasiquotes compiled into bytecode at runtime. Catalyst transforms SQL expressions into Scala ASTs, which are compiled and executed.
Spark 3 - Adaptive Query Execution
In Apache Spark 3, released in 2020, Adaptive Query Execution (AQE) was introduced to tackle such problems with the ability to adjust query plans based on runtime statistics collected during the execution.
Spark operators are typically pipelined and executed in parallel processes. A shuffle or broadcast exchange breaks the pipeline into query stages, where each stage materializes intermediate results. The next stage can only begin once the previous stage is complete. This pause creates an opportunity for re-optimization, as data statistics from all partitions are available before the following operations start.
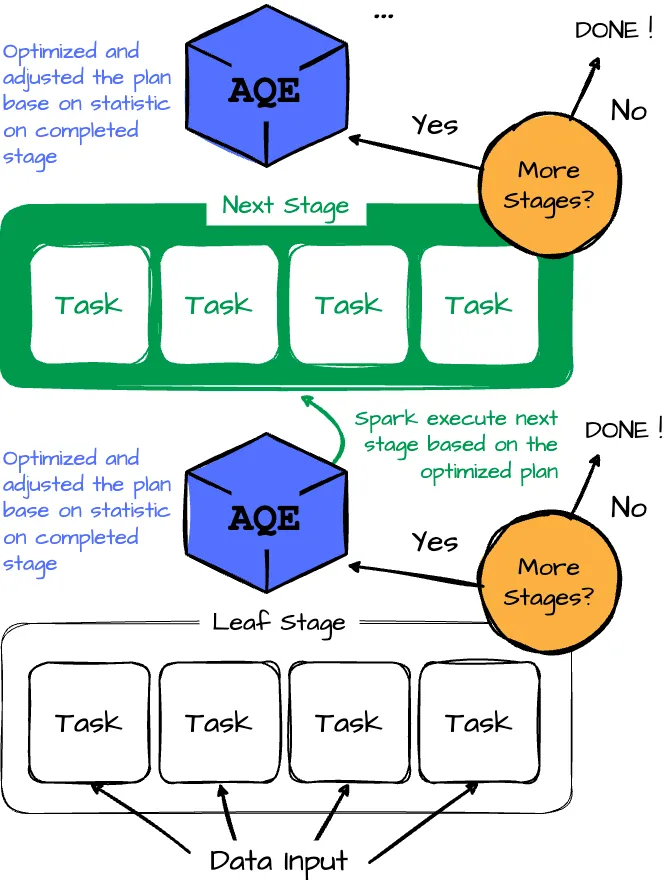
Let’s overview the flow of the AQE framework:
- The Adaptive Query Execution (AQE) framework starts by executing leaf stages, which do not depend on other stages. (reading data input)
- Once one or more of these stages complete materialization, the framework marks them as complete in the physical query plan. It updates the logical query plan with runtime statistics from the completed stages.
- The framework uses these new statistics to run the optimizer, applying a selected list of logical optimization rules, the physical planner, and physical optimization rules, including adaptive-execution-specific rules like coalescing partitions and skew join handling.
- The AQE framework identifies and executes new query stages with the newly optimized plan.
- The execute-reoptimize-execute process repeats until the entire query is completed.
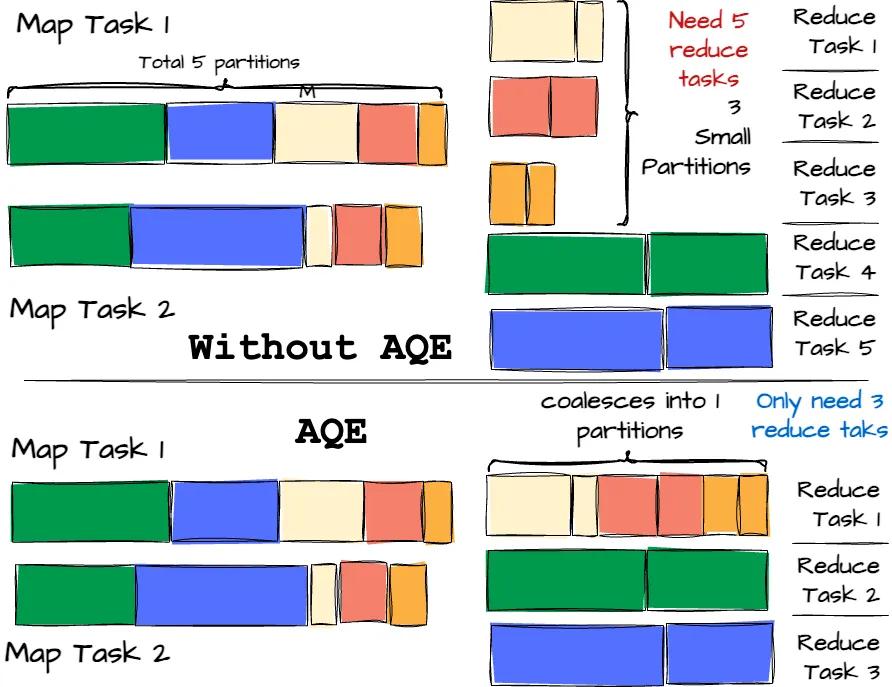
Dynamically coalescing shuffle partitions.
Shuffle operations can significantly impact performance when running queries on large datasets in Spark. Shuffle is expensive because it requires moving data around to redistribute it for downstream operators. Thus, the number of partitions directly affects the shuffle performance. However, determining the optimal number in the first place is challenging:
- Too few partitions can result in large partitions that may cause tasks to spill data to disk.
- Too many partitions lead to small partitions, causing inefficient I/O with numerous small network data fetches.
To address this, the user can start with a relatively large number of shuffle partitions and then combine smaller adjacent partitions at runtime by analyzing shuffle file statistics with the help of AQE. This approach helps balance partition sizes and improve query performance. Let’s visit the example below for a better understanding
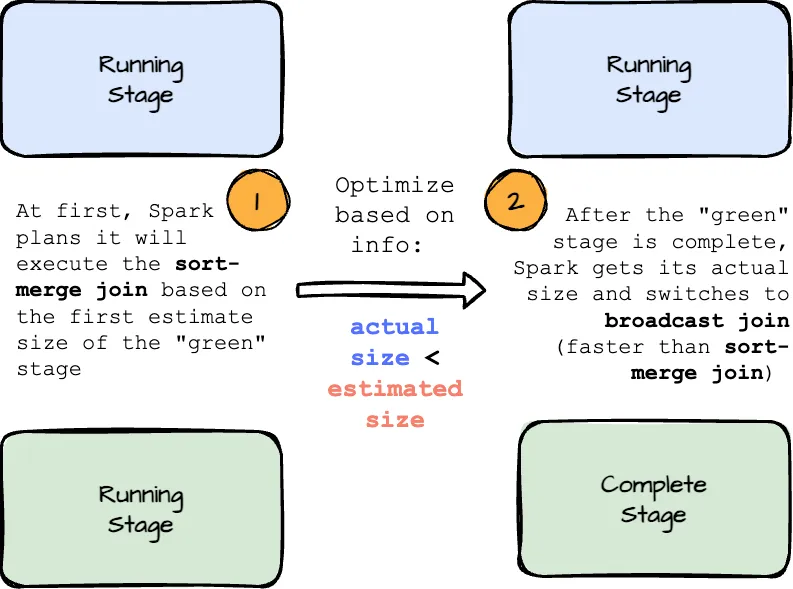
Dynamically switching join strategies.
Spark offers several join strategies, with broadcast hash join typically the most efficient when one side of the join comfortably fits in memory. Spark initially plans a broadcast hash join if it estimates that the join relation’s size is below a specified threshold at the planning phase. However, this estimate can be off due to factors like highly selective filters or complex joint operations.
To address this, Adaptive Query Execution (AQE) now replans the join strategy at runtime based on the actual size of the join relation collected during the execution.
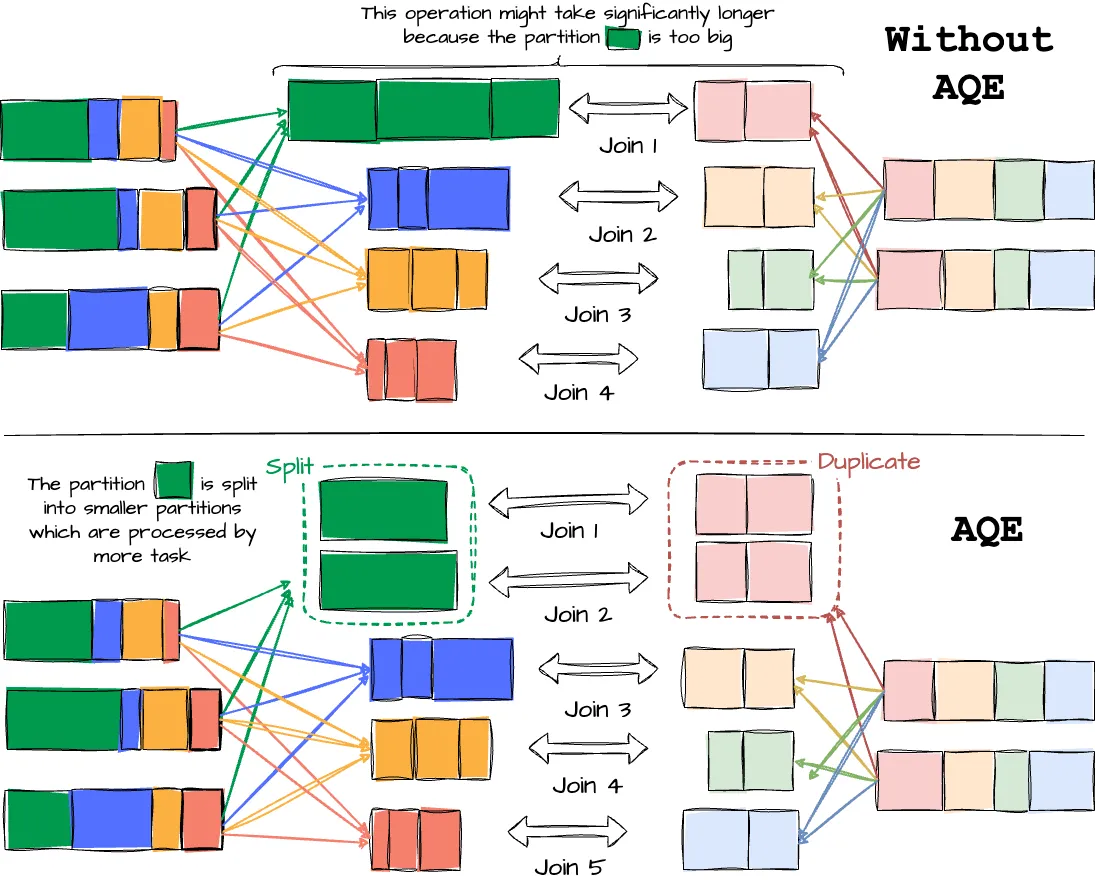
Dynamically optimizing skew joins.
Data skew happens when data is not distributed evenly across partitions in a cluster, which can impact query performance, especially during joins. The AQE skew joins optimization addresses this by automatically detecting skew from shuffle file statistics. It then splits the skewed partitions into smaller partitions. If we don’t employ AQE, our application will have a straggler executor (the one that lags significantly behind the others), which increases the system’s overall latency. With the optimization in place, the data from the straggler is split into smaller partitions and is in charge of more executors, which helps improve the overall performance.