
Overview
To the spark perform work parallel, it split the data into chunks (partitions). A partition is collection of row or data, that sit on one physical machine in the cluster.
The core data structure is immutable, the spark do not carry out any transformation until we call an action. When an action have finished, It will return a new object and don’t modify previous object
There are 2 types transformation:
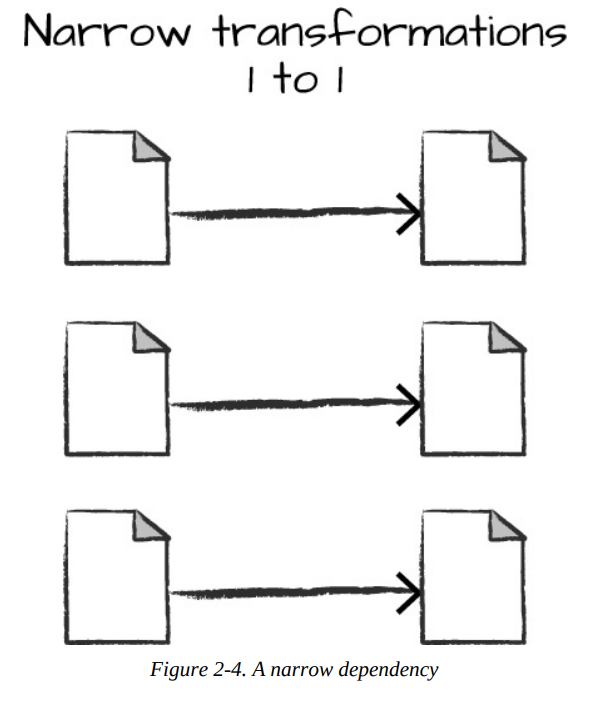
- narrow dependencies: each input partition will contribute to only one output partition
- wide dependencies: the input partition will contribute to many output partitions (shuffle)
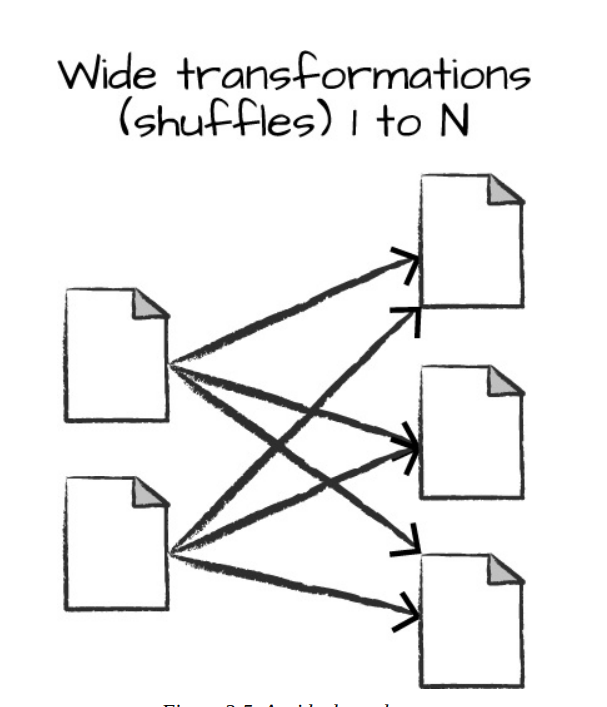
Shuffle
Shuffle whereby Spark will exchange partitions across the cluster
How do the narrow and wide transformation work?
- For the narrow transformation, the spark will automatically perform an operation call pipelining, that will performed in-memory.
- For the wide transformation, the spark need to write the result to disk
In spark, reading data is also transformation, and is therefore a lazy operation
Sort
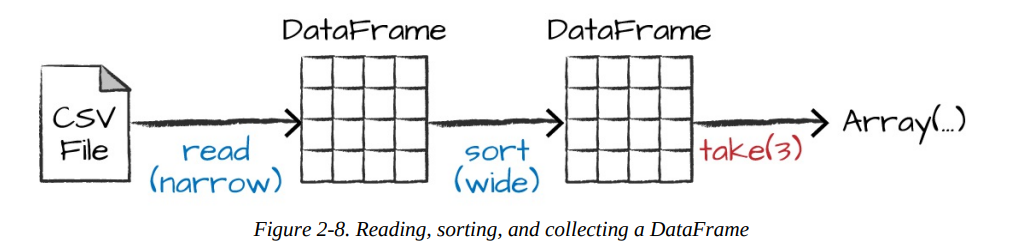
Sort does not modify the DataFrame. We use sort as a transformation that returns a new DataFrame by transforming the previous DataFrame. Let’s illustrate what’s happening when we call take on that resulting DataFrame
 Spark uses an engine called Catalyst that maintains its own type information through the planning and processing of work. Spark types map directly to the different language APIs that Spark maintains and there exists a lookup table for each of these in Scala, Java, Python, SQL, and R.
Spark uses an engine called Catalyst that maintains its own type information through the planning and processing of work. Spark types map directly to the different language APIs that Spark maintains and there exists a lookup table for each of these in Scala, Java, Python, SQL, and R.
References
- Spark: The Definitive Guide by Bill Chambers and Matei Zaharia.