
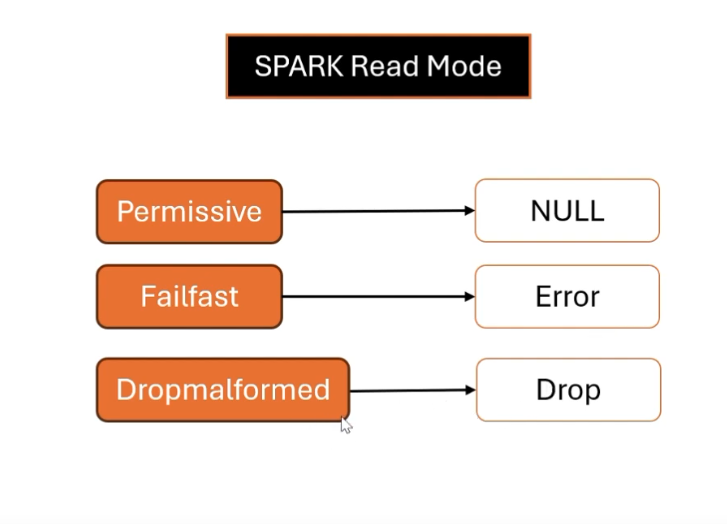
Read mode
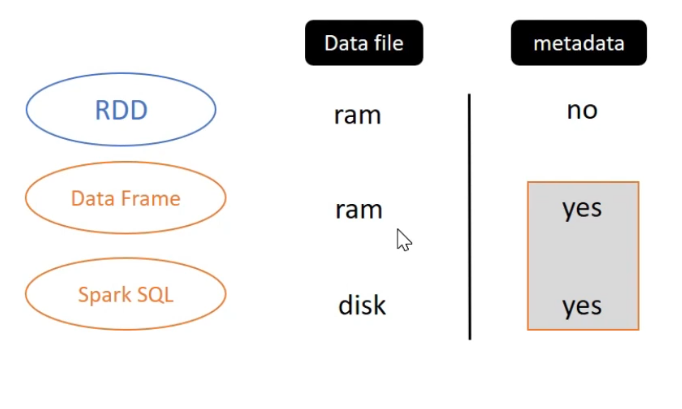
The different of RDD, DataFrame and Spark SQL
What happen when spark session closed?
If Spark Session is closed, the data file’s Spark SQL will still exists in disk. For RDD and DF will be cleared
Spark metadata
The Spark metadata is stored in meta store. When Spark conduct to execute a query , It will combine data files and metadata.
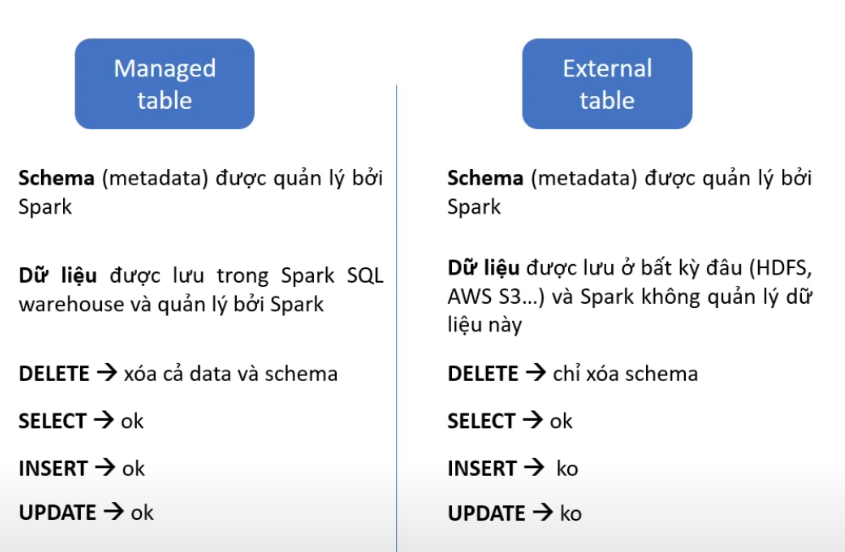
Managed table
Information
Both the location of data files and schema, that will be managed by spark. When Spark drop table, both data files and schema will be removed.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.config('spark.sql.datawarehouse.dir', '~/dwh') \
.enableHiveSupport() \
.getOrCreate()
order_df = spark.read.csv('~/data/order.csv', header=True, inferSchema=True)
order_df.createOrReplaceTempView('orders_temp')
# create orders table from temp
spark.sql('CREATE TABLE IF NOT EXISTS default.orders AS SELECT * FROM orders_temp')
# show data
spark.sql('show tables in default').show()
# describe orders table
spark.sql('DESCRIBE EXTENDED default.orders').show(30, False)
# drop table
spark.sql('DROP TABLE IF NOT EXISTS default.orders')
# Recheck
spark.sql('SELECT * FROM default.orders')
# Occuring an error and check folder, we will realize that all data files is deleted.In the result from describe orders table, we will see some information of this table, as: Type, Location, Statistics,…
External table
Information
The location of data files, we can store anywhere, when spark drop table, it only remove schema of this table, not remove data files (spark isn’t managed).
spark.sql("CREATE EXTERNAL TABLE IF NOT EXISTS default.orders_external (order_id integer, ...) USING CSV OPTIONS (PATH '~/data/order.csv')")
# describe orders table
spark.sql('DESCRIBE EXTENDED default.orders_external').show(30, False)
# drop table
spark.sql('DROP TABLE IF NOT EXISTS default.orders_external')
# Recheck
spark.sql('SELECT * FROM default.orders_external')
# Occuring an error and check data files location, we will realize that all data files is still exists.CURD in external table
We can’t Insert and update the external table. Because Spark just read data from data files, it isn’t manage table. Therefore, we are only read data and delete their schema.
Conclusion
- External table is often used by many team, so we need to ensure data is consistency.