
Overview
Presto was developed by Facebook, they use SQL to address he growing need to extract insights from large amounts of data for analytics.
Definition
Presto was developed by Facebook, they use SQL to address he growing need to extract insights from large amounts of data for analytics. Presto is a distributed SQL query engine that processes hundreds of petabytes of data and quadrillions of rows daily at Facebook.
Characteristics:
- It can run hundreds of resource-intensive queries at the same time.
- It can scale to thousands of workers.
- It can query multiple data sources, even in the same query.
- It can support many use cases with different constraints and performance characteristics.
- It promises to operate at high performance.
Architecture
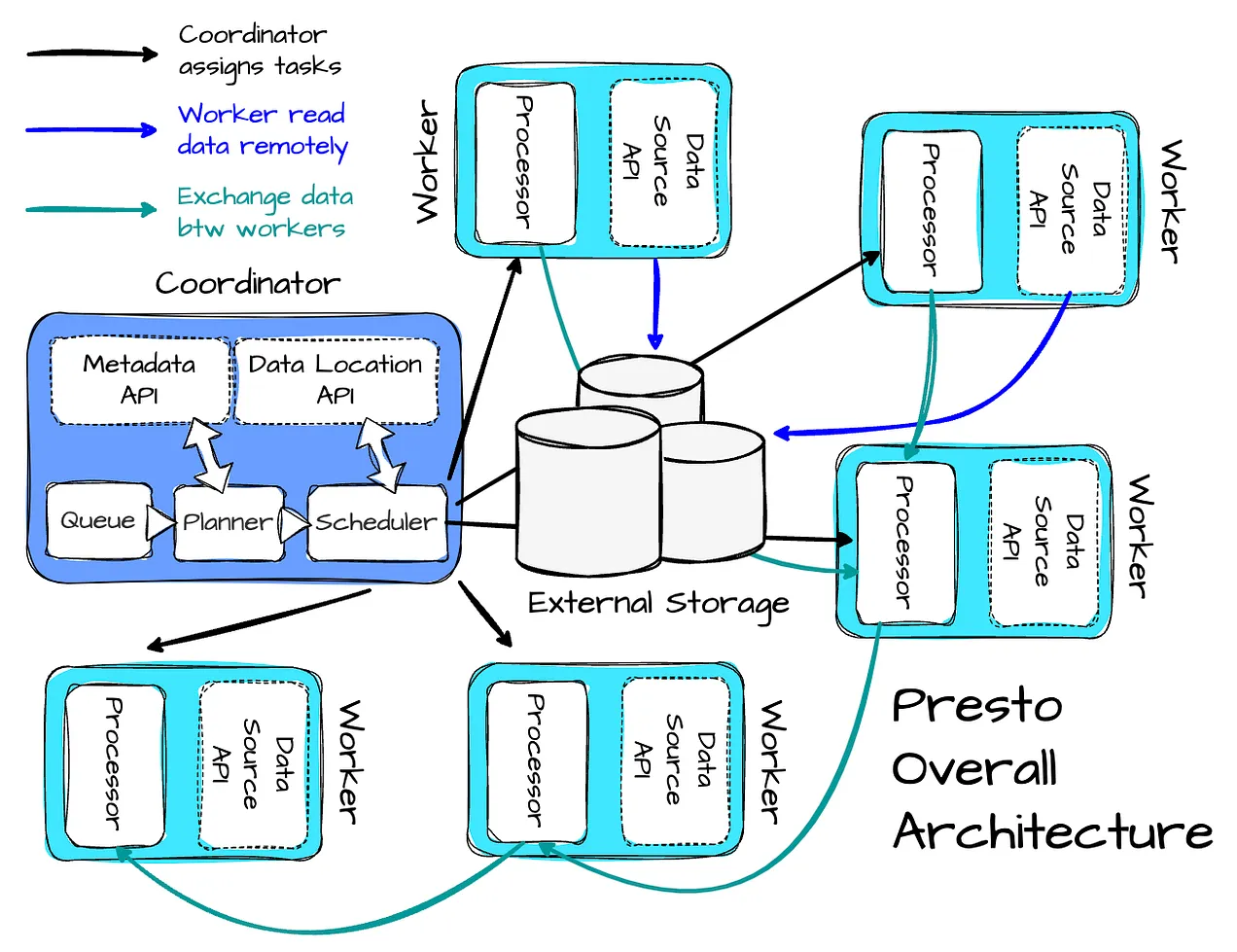 Image created by Vu Trinh
A Presto cluster has a coordinator node and a set of worker nodes:
Image created by Vu Trinh
A Presto cluster has a coordinator node and a set of worker nodes:
- The coordinator parses, plans, and orchestrates queries.
- The workers execute the query.
The presto flow:
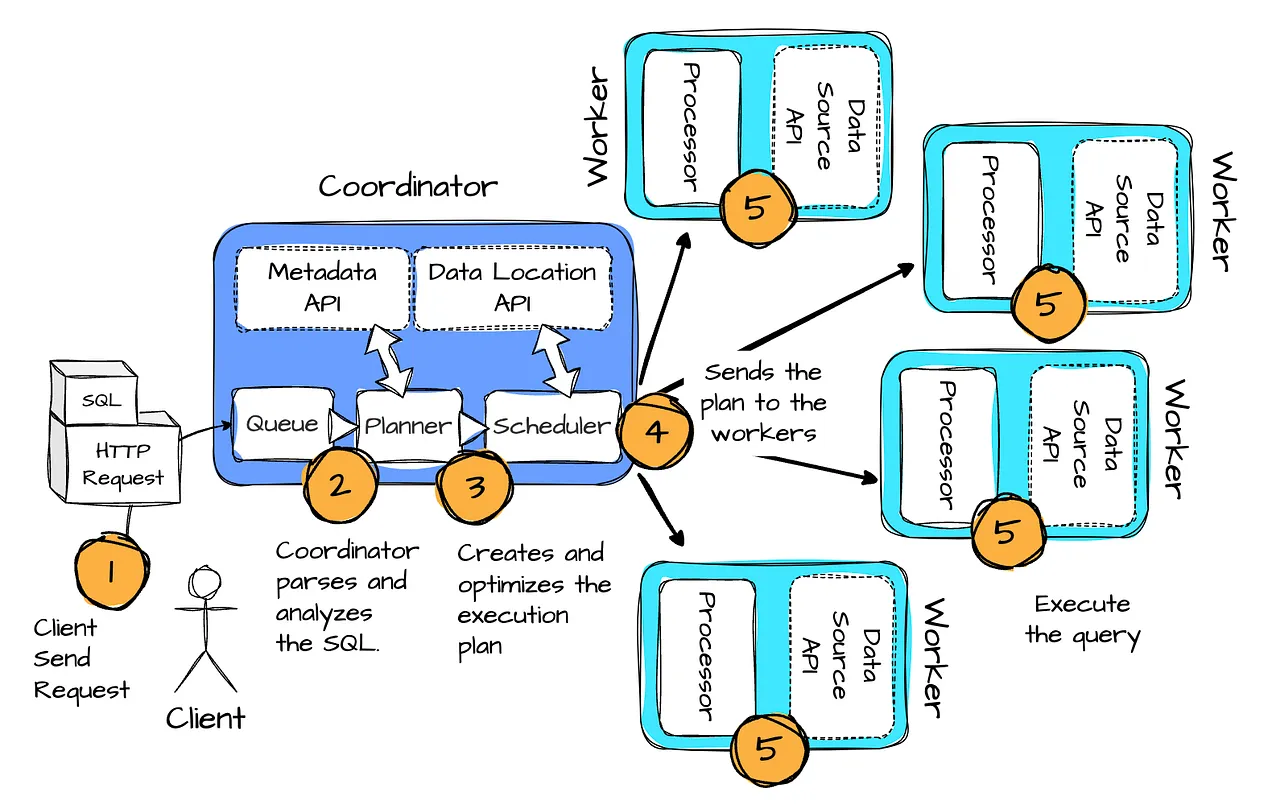 Image created by Vu Trinh
Image created by Vu Trinh - The client sends an HTTP request with the SQL statement to the coordinator.
- The coordinator parses and analyzes the SQL.
- It then creates and optimizes the execution plan.
- The coordinator sends the plan to the workers.
- Workers start executing the tasks, operating on splits, which are chunks of data in an external storage system.
- Workers’ inputs are remote splits or intermediate results from upstream workers. Workers store intermediate data in memory as much as possible. They also support many plugins for customization:
- Custom data types.
- Custom function.
- Custom access control implementations.
- Custom queuing policies.
- Custom connectors enable Presto to communicate with external data stores through the Connector API, which has four parts: the Metadata API, Data Location API, Data Source API, and Data Sink API.
Key Design Decision
SQL Dialect
Presto adheres to the ANSI SQL to achieve broad compatibility. Facebook also selected extensions from ANSI SQL for Presto, such as lambda expressions and higher-order functions, to improve usability with complex data types like maps and arrays.
Client Interface
Presto provides multiple client interfaces:
- A RESTful HTTP interface for clients.
- A command-line interface.
- A JDBC client, enabling compatibility with BI tools like Tableau.
Query Planning And Optimization
The logical planner generates an intermediate representation (IR) of the query plan based on the syntax tree. The IR is a plan nodes tree. Each node is a physical or logical operation; it receives input from its children.
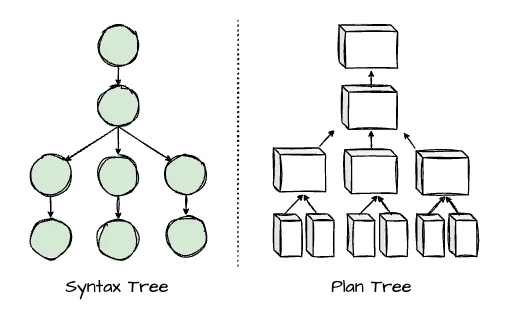 Image created by Vu Trinh
The query optimizer creates the physical plan from the logical plan. This process uses a set of transformation rules, such as predicate and limit push down, column pruning, and decorrelation.
Image created by Vu Trinh
The query optimizer creates the physical plan from the logical plan. This process uses a set of transformation rules, such as predicate and limit push down, column pruning, and decorrelation.
Data Layouts
Presto leverages the physical layout of data provided by the connector’s Data Layout API to optimize queries. Some layout information includes data location, its partitioning schema, the data index, and how they sort or group the data.
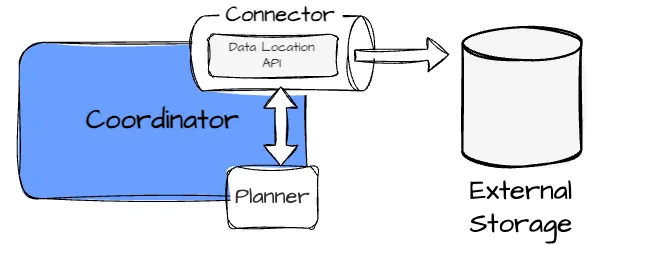 Image created by Vu Trinh
For a table, the connector can return more than layout information; the optimizer can select the most efficient layout for the query. (e.g., leverage partitioning but ignoring the sorting)
Image created by Vu Trinh
For a table, the connector can return more than layout information; the optimizer can select the most efficient layout for the query. (e.g., leverage partitioning but ignoring the sorting)
Predicate Pushdown
Presto can push down predicates to the data source through connectors to improve filtering efficiency. The optimizer will talk with the connector to decide when to execute this technique.
Inter-node parallelism
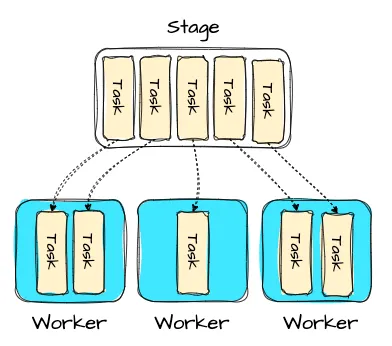 Image created by Vu Trinh
The optimizer also decides which plan stages can run parallel across workers. A stage can have many tasks, executing the same logic on a subset of input data. A shuffle happens when exchanging data between stages. Data shuffling increases latency and uses a lot of CPU and memory. Thus, the optimizer must consider the number of shuffles in a plan.
Image created by Vu Trinh
The optimizer also decides which plan stages can run parallel across workers. A stage can have many tasks, executing the same logic on a subset of input data. A shuffle happens when exchanging data between stages. Data shuffling increases latency and uses a lot of CPU and memory. Thus, the optimizer must consider the number of shuffles in a plan.
Intra-node parallelism
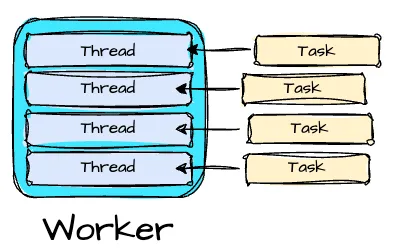 Image created by Vu Trinh
The optimizer can identify and parallelize sections in a plan stage across threads on a single worker. This is much more efficient than inter-node parallelism; threads can share memory data, such as hash tables or dictionaries, with less overhead.
Image created by Vu Trinh
The optimizer can identify and parallelize sections in a plan stage across threads on a single worker. This is much more efficient than inter-node parallelism; threads can share memory data, such as hash tables or dictionaries, with less overhead.
Scheduling
To execute a query, the engine makes two scheduling decisions:
- Stage Scheduling: Presto supports two policies: all-at-once and phased. The first schedules all stages concurrently, which benefits latency-sensitive use cases such as Interactive Analytics. The phased policy executes stages in a topological order. For example, a hash-join will not schedule tasks from the probe phase until it’s finished with the build phase. The phased policy improves memory efficiency for the batch use case.
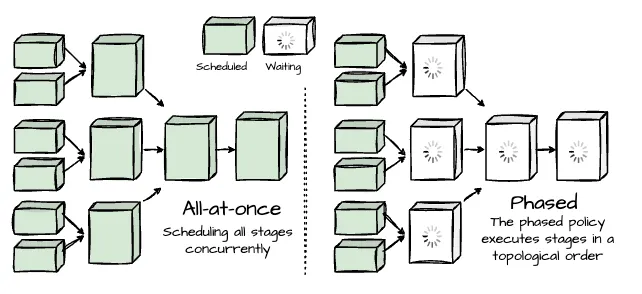 Image created by Vu Trinh
Image created by Vu Trinh - Task Scheduling: The task scheduler categorized stages into leaf and intermediate. The leaf stages read data from the connector, and the intermediate stages process results from other stages. Leaf stages read data from connectors; placement considers network and connector constraints. Intermediate Stages process intermediate results; they can be placed on any worker node.
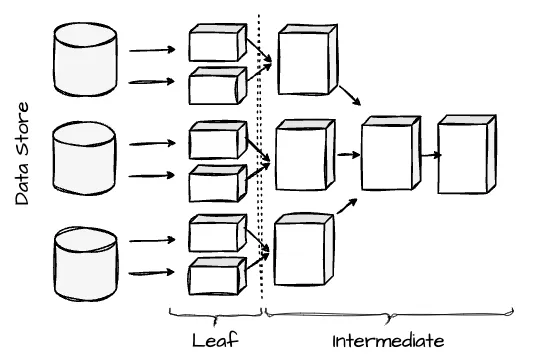 Image created by Vu Trinh
In a leaf stage, the node receives one or more splits (chunks of data) from the external systems. The coordinator must assign one or more splits to a leaf stage task for it to become eligible to run. Intermediate-stage tasks are always eligible to run and finish when all upstream tasks are completed.
Image created by Vu Trinh
In a leaf stage, the node receives one or more splits (chunks of data) from the external systems. The coordinator must assign one or more splits to a leaf stage task for it to become eligible to run. Intermediate-stage tasks are always eligible to run and finish when all upstream tasks are completed.
The coordinator assigns splits after Presto sets up tasks for the worker nodes. Presto asks connectors to enumerate small batches of splits and assigns them to tasks lazily.
This has some benefits:
- Queries that don’t need to process all data, like those with filters or LIMIT clauses, can be canceled early.
- It separates the time it takes to get the first result from the total time it takes to enumerate all splits. This is useful when connectors like Hive might take significant time to list all partitions and files.
- Lazy enumeration prevents storing all split metadata in memory; a Hive connector can handle millions of splits.
- The worker has a queue of assigned splits. The coordinator assigns splits to tasks with the shortest queue, keeping the queue size small and helping manage variations in processing times across different splits and worker performance.
Query Execution
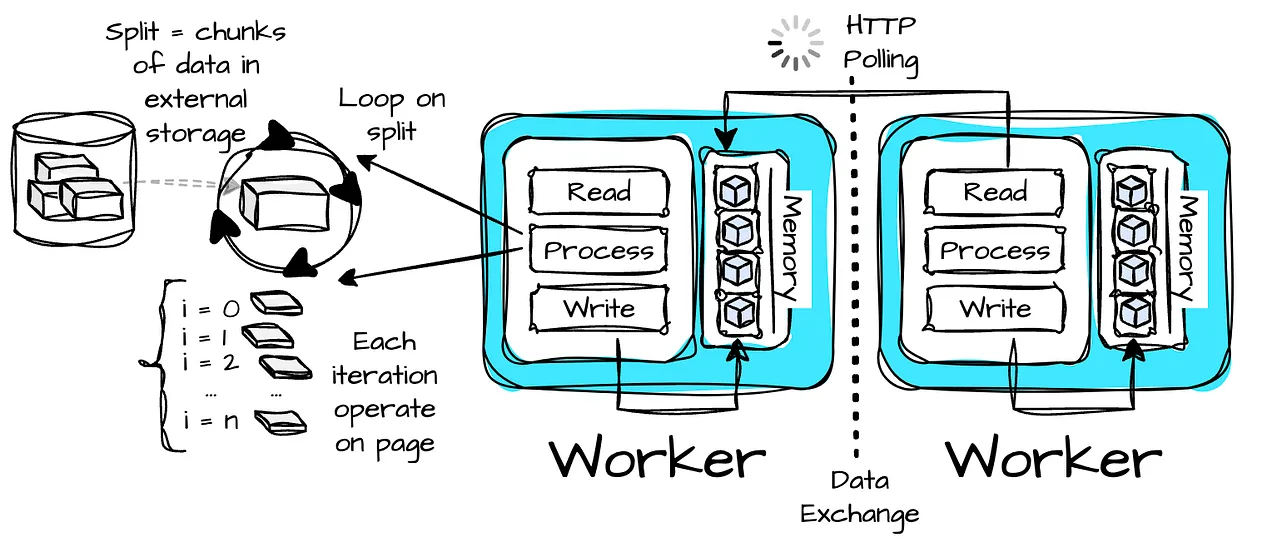 Image created by Vu Trinh
A thread executes in a loop over a split. The data unit the driver loop operates on is a page, a columnar encoding of a sequence of rows.
Presto uses in-memory buffered shuffles over HTTP for efficient data exchange between worker nodes. Workers store produced data in the memory so other workers can consume it by issuing HTTP polling. The engine tunes parallelism to maintain target utilization rates for output and input buffers. Full output buffers cause split execution to stall and take up all memory, while underutilized input buffers add unnecessary processing overhead.
Image created by Vu Trinh
A thread executes in a loop over a split. The data unit the driver loop operates on is a page, a columnar encoding of a sequence of rows.
Presto uses in-memory buffered shuffles over HTTP for efficient data exchange between worker nodes. Workers store produced data in the memory so other workers can consume it by issuing HTTP polling. The engine tunes parallelism to maintain target utilization rates for output and input buffers. Full output buffers cause split execution to stall and take up all memory, while underutilized input buffers add unnecessary processing overhead.
Resource management
Facebook designed Presto’s CPU scheduling mechanism to maximize overall cluster throughput; they prioritize the total CPU time spent processing data.
Presto uses a cooperative multitasking model and schedules concurrent tasks on every worker node to achieve multi-tenancy. A given split can only run on a threat for a maximum execution time slice, called quanta. After that time, the thread will stop processing this split, whether it is finished or not. This approach ensures that no single split takes all the resources and allows for efficient sharing among multiple queries.
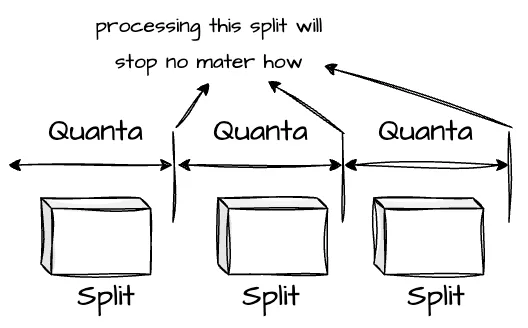 Image created by Vu Trinh
Image created by Vu Trinh
Cooperative multitasking
Cooperative multitasking is a multitasking method used by operating systems where each running process must periodically signal that it has completed its task or that it no longer needs CPU resources to allow other processes to execute. This approach relies on the voluntary cooperation of each process to take control of system resources to other processes.
Presto provides a mechanism for operators to give up control to address the challenges of long-running computations within a cooperative multi-tasking environment. If an operator exceeds its quanta, the scheduler “charges” the task with the thread time used, temporarily reducing its future execution frequency. This adaptability ensures efficient resource sharing even with diverse query shapes.
Instead of predicting resource needs in advance, Presto classifies tasks based on their accumulated CPU time. As a task uses more CPU, it moves to higher queue levels, each receiving a configurable fraction of the available CPU time. This strategy ensures that less demanding queries receive resources, as they accumulate less CPU time and remain in lower queue levels. This reflects the expectation that users prioritize fast responses for interactive queries while being less sensitive about the return time of intensive jobs.
After the CPU, we will see how Presto manages memory resources.
Presto categorizes memory allocations as user or system memory. User memory refers to memory usage that users can estimate based on their understanding of the query and data. System memory represents usage from implementation choices, such as shuffle buffers.
Presto has limits on user and total memory (user + system). It will kill a query requiring a memory resource larger than the cluster’s memory or a per-node limit. These separate limits provide flexibility in managing diverse workloads.
When a worker node’s memory is exhausted, Presto halts task processing on that node. Presto employs several strategies to address memory pressure and prevent cluster instability:
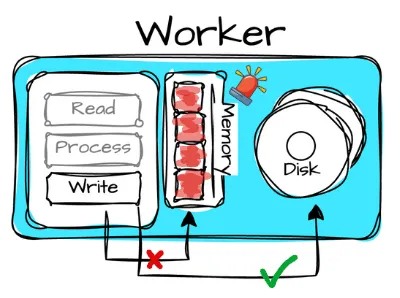
- Spilling: Presto can revoke memory from eligible tasks when a node runs out of memory by writing their in-memory state to disk. Presto prioritizes the process based on task execution time, starting with the longest-running tasks. Of course, spilling to disk will increase the overall query response time. At Facebook, they don’t enable spilling by default because users appreciate the predictable latency of in-memory execution.
 *Image created by Vu Trinh
*Image created by Vu Trinh - Reserved Pool: Another mechanism is the reserved memory pool. Presto divides the node’s memory pool into general and reserved pools. Presto promotes the query to consume memory resources in the reserved pool. The system counts this query’s memory usage against the reserved pool, preventing it from competing with other queries for the general pool.
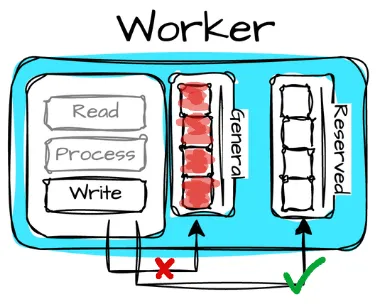 Image created by Vu Trinh
Image created by Vu Trinh
Fault Tolerance
Here are the effects if failures happen:
- Coordinator: If the coordinator fails, the cluster becomes unavailable.
- Worker Node: If a worker node crashes, all queries running on that node will fail
To mitigate the impact of these failures, Presto relies on external mechanisms:
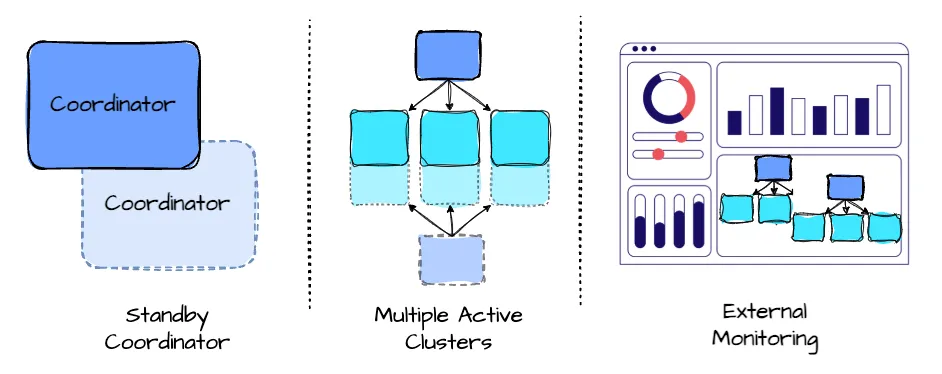 Image created by Vu Trinh
Image created by Vu Trinh
- Standby Coordinators: Facebook employs a backup coordinator, ready to take over if the primary one fails.
- Multiple Active Clusters: Facebook runs multiple active Presto clusters. If one cluster fails, queries can run on another available cluster.
- External Monitoring: External systems monitor Presto clusters, identify failing nodes, and remove them from the cluster.
Optimization
JVM and Code Generation
Because Facebook developed Presto in Java, they leverage the strengths of the Java Virtual Machine (JVM) while minimizing the impact of its limitations**.** Presto utilizes the JVM’s Just-In-Time (JIT) compiler to optimize performance-critical code.
Presto avoids allocating large objects to prevent performance issues and uses flat memory arrays for critical data structures, reducing garbage collection overhead.
File Format Features
Presto utilizes features of columnar file formats to optimize data processing:
- Data Skipping: Custom readers for formats like ORC and Parquet use statistics in file headers and footers (e.g., min-max ranges, Bloom filters) to efficiently skip irrelevant data sections.
- Direct Block Conversion: The readers can directly convert compressed data into Presto’s native block format, enabling efficient processing without decompression overhead.
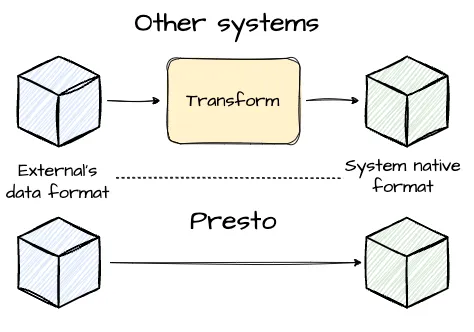 Image created by Vu Trinh
Image created by Vu Trinh
Working with Compressed Data
Presto processes data in its compressed form whenever possible:
- Dictionary and Run-Length-Encoded (RLE) Block Processing: Presto performs operations right on compressed data, taking advantage of their structure for efficient processing. It processes dictionaries in fast, unconditional loops, and their structure is exploited during hash table building for joins and aggregations.
- Compressed Intermediate Results: Presto produces compressed intermediate results, minimizing data movement and storage. For instance, the join processor generates dictionary or RLE blocks for output data, leveraging the existing compressed structures.
Lazy Data Loading
Presto supports lazy materialization, loading, and processing data only when required: Presto only decompresses and decodes data in compressed blocks (dictionary or RLE) when accessing the block’s cells. This minimizes the data fetched and processed, leading to significant performance gains.